즉흥적 프롬프팅에서 에이전트형 엔지니어링으로
저자: Addy Osmani, Shubham Saboo, Sokratis Kartakis
원문: The New SDLC With Vibe Coding, 2026년 5월
이 글은 위 원문을 한국어로 번역하고, 블로그 독자가 읽기 쉽도록 일부 문장을 정리한 번역·정리본이다.
작업 흐름 다이어그램
이 글에서 다루는 바이브 코딩 기반 SDLC는 단순히 코딩 방식의 변화가 아니라, 의도 표현, 컨텍스트 엔지니어링, 에이전트 하네스, 검증, 배포, 개인 지식관리(PKM)가 하나의 루프로 이어지는 시스템이다.

목차
· 서론
· 이 글을 왜 지금 읽어야 하는가
· 이 글의 대상 독자
· 문법에서 의도로의 전환
· AI 에이전트: 간단한 복습
· 바이브 코딩이란 무엇인가
· 스펙트럼: 바이브 코딩에서 에이전트형 엔지니어링으로
· 컨텍스트 엔지니어링: 진짜 핵심 역량
· 새로운 소프트웨어 개발 생명주기
· 압박받는 전통적 SDLC
· AI가 각 단계를 어떻게 바꾸는가
· 공장 모델: 소프트웨어를 만드는 시스템을 만든다
· 하네스 엔지니어링: 모델을 둘러싼 것
· 하네스에는 무엇이 포함되는가
· SDLC 안의 하네스
· 개발자 역할의 진화: 지휘자와 오케스트레이터
· 지휘자: 실시간 직접 지시
· 오케스트레이터: 비동기식 다중 에이전트 위임
· 80% 문제
· 실제 현장의 코딩 에이전트
· 개발자의 하루 속 코딩 에이전트
· 바이브 코딩으로 프로덕션 준비 에이전트 만들기
· AI 개발의 경제학
· 바이브 코딩의 숨은 부채
· 에이전트형 엔지니어링이라는 투자
· 재무적 지렛대로서의 컨텍스트 엔지니어링
· 동적 컨텍스트와 스킬을 통한 효율 확장
· 지능형 모델 라우팅
· 어디서 시작할 것인가
· 개인 개발자를 위해
· 엔지니어링 리더를 위해
· 조직을 위해
· 결론: 새로운 인터페이스로서의 의도
· 주석
서론
컴퓨팅 역사 대부분에서 프로그래밍은 번역의 행위였다. 인간의 언어로 문제를 이해하고, 추상적인 수준에서 해결책을 설계한 뒤, 기계가 실행할 수 있는 문법으로 그것을 다시 표현하는 과정이었다. 각 단계에는 마찰이 있었다. 이제 그 마찰이 무너지고 있다. 소프트웨어 엔지니어링은 고급 프로그래밍 언어의 등장 이후 가장 중대한 변화를 겪고 있다.
소프트웨어 엔지니어링에서 가장 근본적인 변화는 새로운 언어, 프레임워크, 클라우드 서비스가 아니다. 그것은 코드를 직접 작성하는 일에서 의도를 표현하는 일로 이동하고, 지능형 시스템이 그 의도를 작동하는 소프트웨어로 번역하도록 신뢰하는 전환이다.
수십 년 동안 개발자가 기계와 상호작용하는 주된 인터페이스는 문법이었다. 중괄호, 세미콜론, 타입 주석, 프로그래밍 언어의 정확한 문법이 그 인터페이스였다. 그 시대가 끝나가고 있다.
이제 개발자는 “어떻게 만들지”보다 “무엇을 만들고 싶은지”를 표현하는 새로운 패러다임에 들어섰다. 기계는 구현을 맡는다. 인간은 의도, 아키텍처, 판단을 제공한다. 이것은 먼 미래의 이야기가 아니다. 빠르게 늘어나는 전문 개발자들에게 이미 일상의 현실이다. 2026년 초 기준으로 전문 개발자의 85%가 AI 코딩 에이전트를 정기적으로 사용하고, 51%가 매일 사용하며, 새로 작성되는 코드의 약 41%가 AI로 생성되는 것으로 추산된다.
이 변화는 하룻밤 사이에 일어난 것이 아니다. 시작은 단순한 토큰 예측인 자동완성이었다. 그다음에는 함수 전체를 완성할 수 있는 인라인 코드 제안이 등장했다. 이어서 채팅 기반 인터페이스가 개발자가 자연어로 기능을 설명하면 작동하는 구현을 받을 수 있게 했다. 이제는 완전 자율형 에이전트가 저장소를 복제하고, 여러 파일에 걸친 변경을 계획하고, 샌드박스 환경에서 실행하고, 테스트를 돌리고, 풀 리퀘스트까지 제출할 수 있다. 인간이 코드 한 줄을 타이핑하지 않아도 되는 단계에 도달한 것이다.
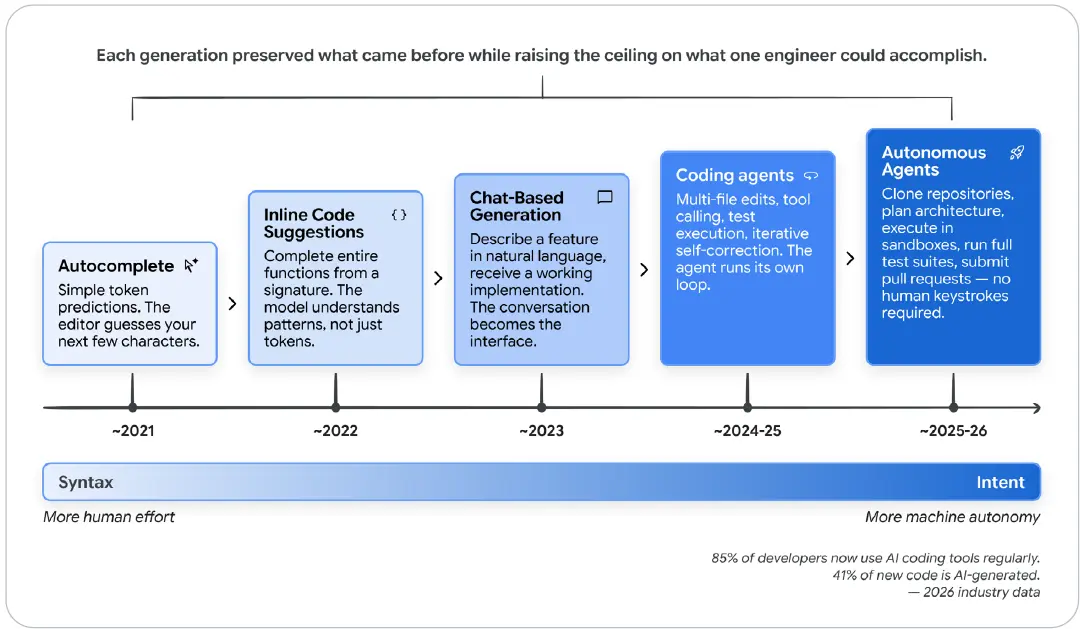
그림 1: 자동완성에서 자율성으로
이 그림은 자동완성(2021년경), 인라인 코드 제안(2022년경), 채팅 기반 생성(2023년경), 코딩 에이전트(2024-2025년경), 자율 에이전트(2025-2026년경)로 이어지는 흐름을 보여준다. 세대가 바뀔 때마다 이전 세대의 기능은 보존하면서 한 명의 엔지니어가 달성할 수 있는 상한을 높였다. 왼쪽의 “문법”에서 오른쪽의 “의도”로 갈수록 인간의 직접 노동은 줄고 기계의 자율성은 커진다.
SDLC, 즉 소프트웨어 개발 생명주기에 대한 함의는 매우 크다. 요구사항 수집부터 배포, 유지보수까지 모든 단계가 AI 역량에 의해 재편되고 있다. 하지만 이 변화는 균일하지도, 단순하지도 않다. 한쪽 끝에는 개발자가 AI에 프롬프트를 던지고 나온 결과를 그대로 받아들이는 느슨한 “바이브 코딩”이 있다. 다른 쪽 끝에는 인간이 아키텍처, 정확성, 품질에 대한 감독권을 유지하면서 AI가 제약, 테스트, 피드백 루프가 정교하게 설계된 시스템 안에서 강력한 구현 엔진으로 작동하는 “에이전트형 엔지니어링”이 있다.
이 구분은 중요하다. CTO에게 “우리 팀은 결제 처리 시스템을 바이브 코딩하고 있습니다”라고 말하면, 그리고 실제로 그래야 하듯, 경고음이 울릴 것이다. 반면 “우리 팀은 인간이 설계한 제약 아래에서 AI가 구현을 맡고, 테스트 커버리지가 정확성을 보장하는 에이전트형 엔지니어링을 실천하고 있습니다”라고 말한다면 완전히 다른 대화가 된다.
이 글은 바로 그 대화를 위한 토대를 제공한다. 우리는 가벼운 바이브 코딩에서 규율 있는 에이전트형 엔지니어링으로 이어지는 스펙트럼을 살펴보고, 개발자의 역할이 코드 작성에서 판단 행사로, 즉 지휘자에서 오케스트레이터로 어떻게 이동하는지 검토하며, 실제로 신뢰할 수 있는 소프트웨어를 만들기 위해 이러한 도구를 어떻게 도입해야 하는지 정리한다.
이 글을 왜 지금 읽어야 하는가
새로운 도구, 역량, 패러다임이 매주 등장한다. 엔지니어링 팀에는 이 지형을 이해할 수 있는 프레임워크가 필요하다. 몇 달 뒤 낡아버릴 스냅샷이 아니라, 구체적인 도구가 바뀌어도 계속 유용한 원칙과 사고 모델이 필요하다.
이 글의 대상 독자
이 글은 AI가 SDLC를 어떻게 재편하고 있는지 이해하고, 프로덕션 소프트웨어가 요구하는 규율을 희생하지 않으면서 새로운 역량을 도입하고자 하는 소프트웨어 엔지니어, 엔지니어링 매니저, 아키텍트, 기술 리더를 위한 글이다. 독자가 현대 소프트웨어 개발 관행에는 익숙하지만 AI나 머신러닝의 세부 사항에는 반드시 익숙하지 않다고 가정한다.
문법에서 의도로의 전환
더 나아가기 전에 에이전트가 무엇인지, 바이브 코딩이 실제로 무엇을 의미하는지에 대한 공통된 그림이 필요하다. 두 용어 모두 너무 많은 의미를 떠안게 되었기 때문에 신중하게 풀어볼 필요가 있다.
AI 에이전트: 간단한 복습
AI 에이전트는 목표를 인식하고, 그 목표에 도달하기 위한 단계를 계획하고, 도구를 통해 행동하고, 결과를 관찰하고, 목표가 충족되거나 중단 조건에 도달할 때까지 반복하는 소프트웨어 시스템이다. 챗봇이 응답을 생성한 뒤 다음 프롬프트를 기다린다면, 에이전트는 자기만의 루프를 실행한다. 사용자가 맨 위에 목표를 주면, 에이전트는 각 단계에서 다음에 무엇을 할지 스스로 결정한다.
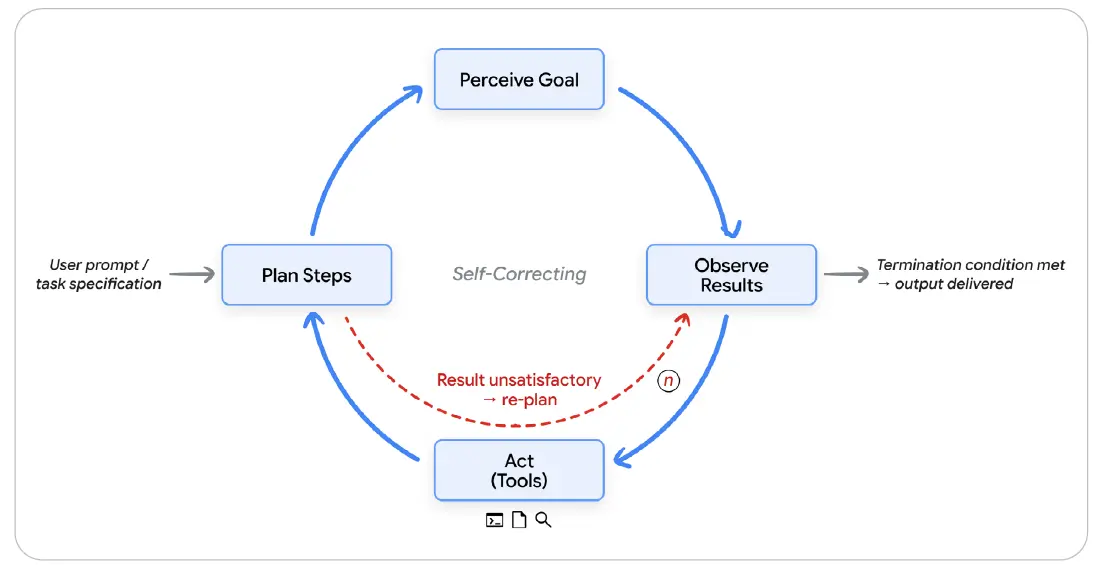
그림 2: 에이전트 루프 - 인식, 계획, 행동, 관찰, 반복
이 다이어그램은 사용자 프롬프트나 작업 명세가 들어오면 에이전트가 목표를 인식하고, 단계를 계획하고, 도구를 통해 행동하고, 결과를 관찰한 뒤, 결과가 만족스럽지 않으면 다시 계획하는 자기교정 루프를 보여준다. 종료 조건이 충족되면 산출물이 제공된다.
모든 에이전트는 단순하든 정교하든 다섯 가지 구성 요소로 이루어진다. 2025년 11월에 나온 Introduction to Agents 백서는 각각을 자세히 다룬다. 여기서는 짧게 요약한다.
· 모델은 추론 엔진이다. 현재 컨텍스트를 읽고, 다음에 무엇이 일어나야 하는지 결정하며, 다음 생각, 다음 도구 호출, 또는 다음 메시지를 생성한다.
· 도구는 모델을 세계와 연결한다. 여기에는 에이전트가 호출할 수 있는 API, 실행할 수 있는 코드, 질의할 수 있는 데이터베이스, 위임할 수 있는 다른 에이전트가 포함된다.
· 메모리는 상태다. 과거 상호작용을 기억하고, 프로젝트별 규칙을 검색하고, 세션을 넘어 컨텍스트를 유지하여 에이전트가 매번 빈 상태에서 시작하지 않도록 한다.
· 오케스트레이션은 루프를 실행하는 코드다. 각 모델 호출을 위한 컨텍스트를 조립하고, 도구 호출을 디스패치하고, 결과를 캡처하며, 계속할지 여부를 결정한다.
· 배포는 프로토타입을 서비스로 바꾸는 것이다. 호스팅, 신원 관리, 관측 가능성, 에이전트가 실행되는 프로덕션 인프라가 여기에 포함된다.
이 구성 요소들은 연속적인 루프 안에서 함께 작동한다. 임무를 받고, 상황을 살피고, 생각하고, 행동하고, 관찰하고, 반복한다. 이 루프는 모든 에이전트의 심장이다. 이 글의 나머지 내용과 과정 전체의 모든 내용은 결국 이 루프의 변형이다.
바이브 코딩이란 무엇인가
2025년 2월, Andrej Karpathy는 소프트웨어 엔지니어링 커뮤니티 전반에 크게 반향을 일으킨 새로운 프로그래밍 방식에 대해 글을 올렸다. 그는 “바이브에 완전히 몸을 맡기고, 지수적 성장을 받아들이며, 코드가 존재한다는 사실조차 잊어버리는” 접근이라고 설명했다. 이 방식에서 개발자는 자연어로 원하는 것을 설명하고, AI의 출력을 받아들이며, 무언가 깨지면 오류 메시지를 다시 프롬프트에 복사해 넣고 AI에게 고치라고 요청한다.
이 용어가 빠르게 퍼진 이유는 그것이 실제로 많은 개발자들이 이미 하고 있던 방식을 정확히 포착했기 때문이다. 많은 개발자들이 이미 그렇게 일하고 있었지만, 그 방식에 이름이 없었을 뿐이다. 몇 달 만에 “바이브 코딩”은 모든 AI 보조 개발 워크플로를 가리키는 흔한 표현이 되었고, 그 결과 혼란도 생겼다. 숙련된 엔지니어가 잘 명세된 기능을 구현하기 위해 AI 어시스턴트를 사용하는 것도 “바이브 코딩”인가? 팀이 세심하게 계획한 아키텍처를 실행하기 위해 AI 에이전트를 사용하는 것도 그런가? 이 용어가 너무 넓게 적용되면서 의미가 흐려지기 시작했다.
2026년 초, Karpathy 본인도 처음의 프레이밍이 지나치게 좁았음을 인정하며 스펙트럼의 더 규율 있는 끝을 설명하기 위해 “에이전트형 엔지니어링”이라는 용어를 제시했다.
스펙트럼: 바이브 코딩에서 에이전트형 엔지니어링으로
바이브 코딩과 에이전트형 엔지니어링을 이분법으로 보기보다, 두 끝점을 가진 스펙트럼으로 보는 편이 더 유용하다. 핵심 차이는 AI를 사용하느냐가 아니다. AI의 출력 주변에 얼마나 많은 구조, 검증, 인간 판단을 둘러두느냐이다.
표 1: 바이브 코딩에서 에이전트형 엔지니어링으로 이어지는 스펙트럼
| 차원 | 바이브 코딩 | 구조화된 AI 보조 코딩 | 에이전트형 엔지니어링 |
| 의도 명세 | 느슨한 자연어 프롬프트 | 예시와 제약을 포함한 상세 프롬프트 | 공식 명세, 아키텍처 문서, 메모리 파일 |
| 검증 | “작동하는 것처럼 보이는가?” | 수동 테스트, 부분 점검 | 자동화된 테스트 스위트, CI/CD 게이트, LM 평가자 |
| 코드베이스 이해 | 최소 수준. 개발자가 생성된 코드를 읽지 않을 수도 있음 | 핵심 경로에 대한 선택적 검토 | 아키텍처에 대한 포괄적 검토. AI는 구현 세부를 처리 |
| 오류 처리 | 오류 메시지를 AI에 복사해 다시 붙여넣음 | 개발자가 근본 원인을 진단하고 AI가 수정 구현 | 에이전트가 정해진 범위 안에서 자가 진단. 인간은 아키텍처 문제 처리 |
| 적합한 범위 | 프로토타입, 스크립트, 개인 프로젝트, 해커톤 | 기존 코드베이스 안의 기능 | 프로덕션 시스템, 팀 규모 개발 |
| 위험 프로필 | 높음. 버려도 되는 코드에는 허용 가능 | 중간. 주요 체크포인트에서 인간 판단 필요 | 낮음. 모든 단계에서 체계적 검증 수행 |
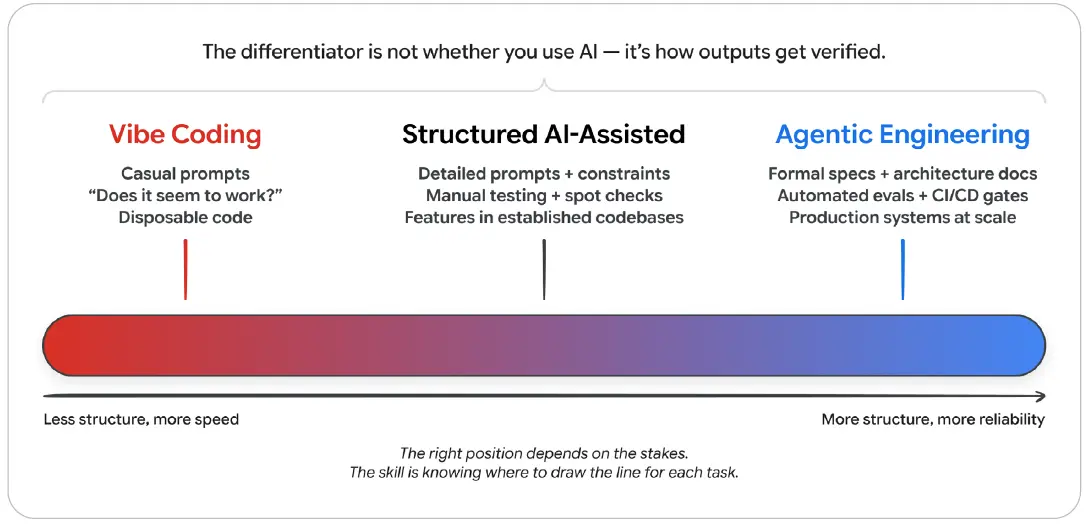 그림 3: 바이브 코딩에서 에이전트형 엔지니어링으로 이어지는 스펙트럼
그림 3: 바이브 코딩에서 에이전트형 엔지니어링으로 이어지는 스펙트럼
이 그림은 왼쪽의 바이브 코딩에서 오른쪽의 에이전트형 엔지니어링으로 갈수록 구조가 많아지고 신뢰성이 높아진다는 점을 보여준다. 핵심 차이는 AI를 사용하느냐가 아니라 출력이 어떻게 검증되는가다.
실무 팁:
이 스펙트럼에서 올바른 위치는 작업의 중요도에 따라 달라진다. 주말 프로토타입은 순수한 바이브 코딩이어도 된다. 금융 거래를 처리하는 프로덕션 API는 에이전트형 엔지니어링을 요구한다. 실제 업무 대부분은 그 중간 어딘가에 있으며, 역량은 각 작업에서 선을 어디에 그어야 하는지 아는 데 있다.
두 끝을 가르는 가장 큰 차이는 출력이 검증되는 방식이다. 바이브 코딩에서는 검증이 선택 사항이다. 개발자가 코드를 실행하고 그럴듯해 보이는지 확인한다. 에이전트형 엔지니어링에서는 두 가지 메커니즘이 함께 작동한다. 테스트는 시스템의 결정론적 부분을 검증한다. 예를 들어 이 입력을 받은 함수가 저 출력을 내는지 확인한다. 평가, 즉 eval은 결정론적이지 않은 부분을 검증한다. 에이전트가 올바른 단계 궤적을 따랐는지, 적절한 도구를 선택했는지, 최종 응답이 품질 기준을 충족하는지 확인한다. 테스트는 코드로 확인되고, eval은 라벨링된 데이터셋, 채점 루브릭, LM 평가자로 확인된다. 둘 다 없다면 프롬프트가 아무리 정교해도 그 실천은 언제나 바이브 코딩에 머문다.
컨텍스트 엔지니어링: 진짜 핵심 역량
분야가 성숙하면서 하나의 핵심 통찰이 드러났다. AI가 생성하는 코드의 품질은 프롬프트의 재치보다 제공되는 컨텍스트의 품질에 더 크게 좌우된다. 이러한 깨달음은 컨텍스트 엔지니어링이라는 개념으로 이어졌다. 컨텍스트 엔지니어링은 AI 에이전트에게 코드베이스, 아키텍처, 관례, 의도에 대한 풍부하고 구조화된 정보를 제공하는 실천이다.
개발자는 여섯 가지 주요 컨텍스트 유형을 고려해야 한다.
· 지시사항: 에이전트의 핵심 역할, 목표, 운영 경계.
· 지식: 검색된 문서, 아키텍처 다이어그램, 도메인별 데이터.
· 메모리: 단기 세션 로그, 즉 방금 일어난 일, 그리고 장기 영속 상태, 즉 프로젝트가 무엇인지에 대한 정보.
· 예시: 몇 가지 행동 시연과 코드베이스 참조 패턴.
· 도구: 에이전트가 호출할 수 있는 API, 스크립트, 외부 서비스의 정확한 정의.
· 가드레일: 강제 제약, 형식 규칙, 안전성 검증.
AI 코드 생성에서 컨텍스트 엔지니어링은 이 여섯 요소 중 무엇을 에이전트가 처음부터 가지고 있어야 하고, 무엇을 필요할 때 검색할 수 있어야 하는지를 신중하게 조율하는 일이다. 여기서 정적 컨텍스트와 동적 컨텍스트의 중요한 분리가 생긴다.
정적 컨텍스트는 항상 로드된다. 시스템 지시사항, 규칙 파일(AGENTS.md, CLAUDE.md, GEMINI.md), 전역 메모리, 페르소나 정의가 여기에 속한다. 이것은 에이전트가 누구인지, 어떻게 행동해야 하는지를 정의한다. 정적 컨텍스트는 관련성이 있든 없든 모든 상호작용에 토큰으로 들어가기 때문에 비용이 크다.
동적 컨텍스트는 필요할 때 로드된다. 작업 매칭에 의해 트리거되는 스킬 지시사항, 실행 중 검색되는 도구 결과, RAG 파이프라인에서 가져오는 문서, 윈도우 처리된 세션 기록이 여기에 속한다. 동적 컨텍스트는 정보가 필요할 때에만 토큰 비용을 지불하므로 효율적이다.
무엇을 정적 컨텍스트에 넣고 무엇을 동적 컨텍스트에 넣을지 결정하는 일은 진짜 엔지니어링 트레이드오프다. 정적 컨텍스트가 너무 많으면 토큰을 낭비하고 신호를 흐린다. 너무 적으면 에이전트가 중요한 규칙을 잊는다. 가장 좋은 시스템은 이 경계를 1급 아키텍처 결정으로 다루며, 다른 설정과 마찬가지로 검토하고 버전 관리한다.
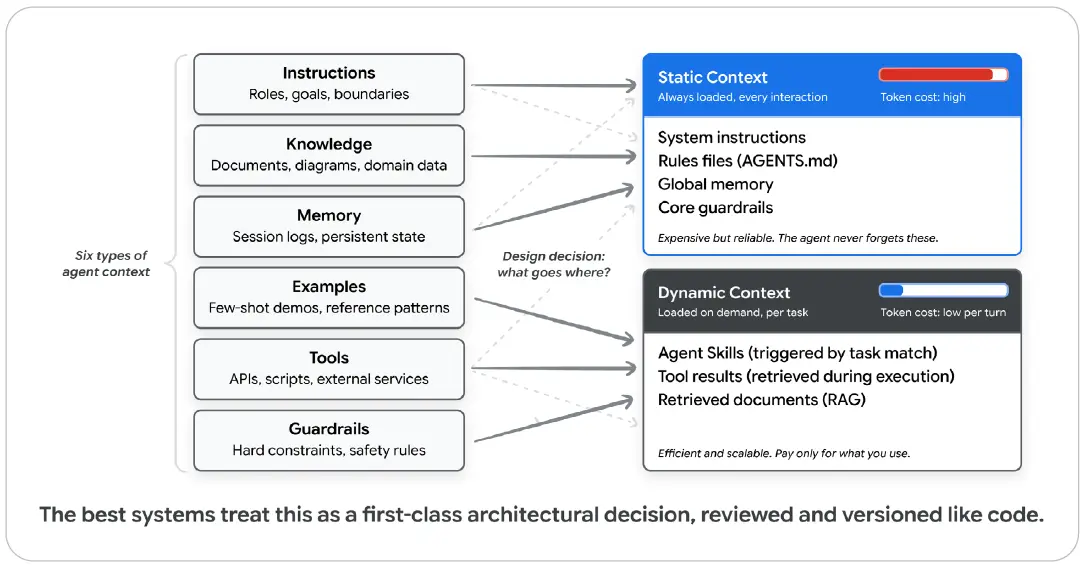
그림 4: 컨텍스트 엔지니어링 - 정적 컨텍스트와 동적 컨텍스트
이 그림은 지시사항, 지식, 메모리, 예시, 도구, 가드레일이라는 여섯 가지 컨텍스트가 정적 컨텍스트와 동적 컨텍스트로 배치되는 방식을 보여준다. 정적 컨텍스트는 항상 로드되어 비용이 높지만 안정적이고, 동적 컨텍스트는 작업마다 필요할 때 로드되어 효율적이고 확장 가능하다.
동적 컨텍스트를 관리하는 가장 강력한 패턴은 에이전트 스킬이다. 에이전트 스킬은 작업이 요구할 때에만 에이전트가 로드하는 구조화되고 이식 가능한 절차적 지식 패키지다.
모든 전문 지식을 에이전트의 시스템 프롬프트에 박아 넣는 대신, 스킬은 에이전트가 가벼운 일반가로 남아 있다가 점진적 공개를 통해 필요할 때 전문 역할로 변신하게 한다. 에이전트는 시작 시 가벼운 메타데이터만 보고, 작업이 일치하면 전체 지시사항을 로드하며, 명시적으로 필요할 때에만 깊은 참조 자료를 가져온다. 그 결과 에이전트는 수십 개의 전문 역량을 지니면서도 지금 실제로 사용하는 하나에 대해서만 토큰 비용을 낸다.
에이전트 스킬은 주요 코딩 에이전트와 기업 플랫폼 전반에서 빠르게 채택되고 있다. 이는 AI 에이전트 개발을 괴롭혀 온 네 가지 문제를 해결하기 때문이다.
· 과도하게 부풀어 오른 프롬프트에서 발생하는 컨텍스트 부패
· LLM에 절차적 메모리가 없다는 문제
· 다중 에이전트 아키텍처의 운영 부담
· 도구와 벤더를 넘어 이식 가능한 방식이 필요하다는 문제
이 절은 컨텍스트 엔지니어링의 핵심 원칙을 소개했다. 모든 에이전트에 필요한 여섯 가지 컨텍스트, 정적 컨텍스트와 동적 컨텍스트 사이의 트레이드오프, 그리고 이 트레이드오프를 규모 있게 관리하기 위한 핵심 패턴으로서의 에이전트 스킬이다.
이 시리즈의 Day 3 동반 문서인 Context Engineering: Sessions, Skills & Memory는 이러한 아이디어를 더 깊이 다룬다. 세션을 설계하고 관리하는 방법, 스킬을 작성하고 평가하는 방법, 상호작용을 넘어 영속 메모리를 구축하는 방법, 프로덕션 시스템을 위한 토큰 경제를 최적화하는 방법을 설명한다.
“프롬프트 엔지니어링”에서 “컨텍스트 엔지니어링”으로의 전환은 AI와 함께 일하는 방식에 관한 더 깊은 진실을 반영한다. 모델에는 영리하게 표현된 지시문보다 숙련된 인간 개발자가 좋은 일을 하기 위해 필요로 하는 것과 같은 컨텍스트가 더 필요하다. 질문은 “AI가 좋은 코드를 쓰도록 어떻게 속일까?”가 아니다. 질문은 “새 팀원이 효과적으로 기여하려면 무엇을 알아야 하며, 그 지식을 AI가 사용할 수 있는 형태로 어떻게 인코딩할까?”다.
컨텍스트 엔지니어링은 바이브 코딩과 에이전트형 엔지니어링을 잇는 다리다. 또한 이 절과 다음 절을 잇는 다리이기도 하다. 다음 절에서는 모든 모델을 둘러싸고 그것을 유용하게 만드는 구조를 살펴본다.
문법을 작성하는 데서 이 컨텍스트를 엔지니어링하는 일로 초점을 옮기면, 소프트웨어 생성의 병목은 근본적으로 달라진다. 우리는 더 이상 사람이 손으로 보일러플레이트를 타이핑하기를 기다리지 않는다. 우리는 인간의 머리가 경계를 정의하기를 기다린다. 이는 전통적인 소프트웨어 개발 생명주기(SDLC)를 완전히 다시 상상할 것을 요구한다. 이제 소프트웨어를 만드는 데 사용하는 시스템이 전달 속도를 결정하기 때문이다.
새로운 소프트웨어 개발 생명주기
압박받는 전통적 SDLC
소프트웨어 개발 생명주기는 이미 한 차례 큰 변화를 겪었다. 지난 20년 동안 대부분의 기업은 순차적인 폭포수 프로세스에서 반복 모델로 이동했다. 애자일 스프린트, 지속적 통합, DevOps 파이프라인, 빠른 릴리스 주기가 그 예다. 그 변화는 피드백 루프를 짧게 만들고, 테스트를 개발에 더 가까이 붙였으며, 배포를 분기별 이벤트가 아니라 지속적인 프로세스로 만들었다.
AI는 이 주기를 극적으로 압축하지만, 그 압축은 고르지 않다. 예전에는 몇 주가 걸리던 구현이 이제 몇 시간 만에 가능해졌지만, 요구사항, 아키텍처, 검증은 여전히 인간의 속도에 강하게 묶여 있다. 그 결과는 기존 SDLC의 더 빠른 버전이 아니다. 그것은 다른 워크플로다. 단계 사이의 경계가 흐려지고, 반복 주기는 몇 주에서 몇 분으로 짧아지며, 개발자의 역할은 주된 구현자에서 시스템 설계자이자 품질 판단자로 이동한다.
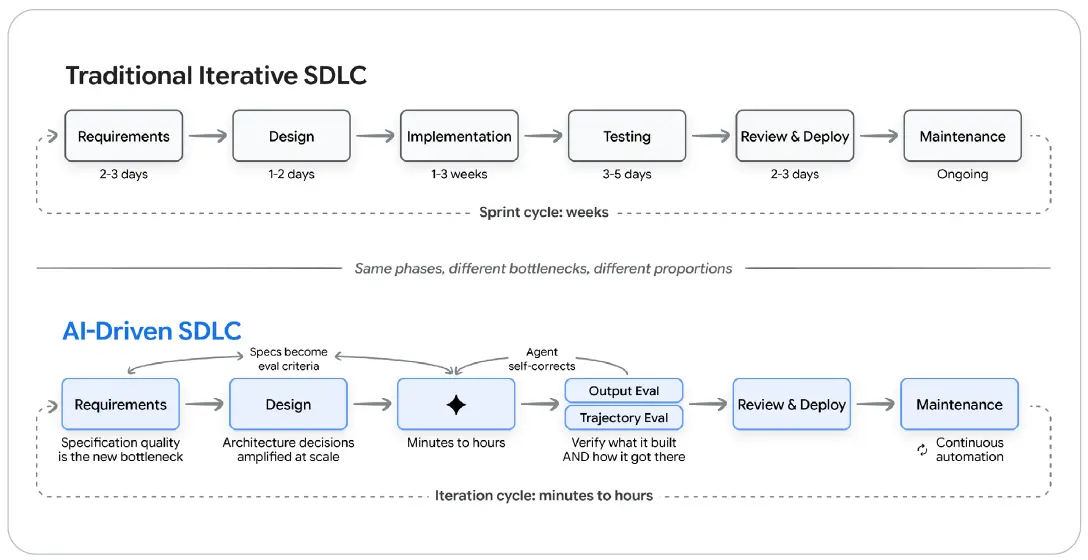
그림 5: 전통적 SDLC와 AI 주도 SDLC
전통적 반복 SDLC에서는 요구사항, 설계, 구현, 테스트, 리뷰와 배포, 유지보수가 주 단위 스프린트로 이어진다. AI 주도 SDLC에서는 명세 품질이 새로운 병목이 되고, 아키텍처 결정은 규모에 따라 증폭되며, 구현은 몇 분에서 몇 시간으로 압축된다. 이후 출력 평가와 궤적 평가가 “무엇을 만들었는가”와 “어떻게 도달했는가”를 함께 검증한다.
변화 속도에 대한 주의: 위에서 단계별로 설명한 그림은 2026년 중반 현재의 AI 주도 SDLC 상태를 반영한다. 변화는 빠르다. 초기 신호는 압축이 구현을 넘어 더 넓게 퍼질 것임을 시사한다. 이미 일부 팀은 개발자가 명세에서 곧바로 리뷰로 넘어가고, AI 에이전트가 구현, 테스트, 배포를 백그라운드에서 처리하는 워크플로를 실험하고 있다. 이 절에서 그은 경계는 12개월 뒤 달라 보일 수 있다. 변하지 않을 것은 인간의 판단, 취향, 그리고 기계가 더 많은 구현을 맡을수록 AI 출력을 검증하는 능력이다.
AI가 각 단계를 어떻게 바꾸는가
요구사항과 계획
요구사항 단계는 역사적으로 의도와 구현 사이의 간극이 가장 넓었던 단계다. 비즈니스 요구를 기술 명세로 번역하는 일은 수동적이고 오류가 나기 쉬운 과정이었으며, 이해관계자가 원하는 것과 엔지니어가 만드는 것 사이에 지속적인 간극을 만들었다.
현대 AI 도구는 요구사항 정제에 직접 참여할 수 있다. 제품 브리프에서 사용자 스토리를 생성하고, 인간이 놓친 엣지 케이스를 찾아내고, 자연어 설명에서 API 스키마를 만들고, 명세 문서에서 인터랙티브 프로토타입을 생성한다. 에이전트형 개발 환경은 개발자가 설명에서 작동하는 프로토타입까지 몇 분 만에 도달하게 하며, 요구사항에서 프로토타입까지의 피드백 루프를 거의 0에 가깝게 줄인다.
요구사항은 더 이상 팀 사이에 전달되는 문서가 아니다. 요구사항은 인간과 AI 사이의 대화가 되며, 그 대화가 명세와 초기 구현을 동시에 만들어낸다.
설계와 아키텍처
아키텍처는 여전히 SDLC에서 가장 인간 중심적인 단계이며, 그럴 만한 이유가 있다. 아키텍처 결정은 근본적으로 트레이드오프에 관한 것이다. 일관성과 가용성, 복잡성과 유연성, 직접 구축과 구매 사이의 선택이 그렇다. 이러한 트레이드오프는 비즈니스 맥락, 조직적 제약, 장기 전략적 고려에 의존하며, AI가 완전히 이해하기 어렵다.
AI는 아키텍처 결정이 내려진 뒤 그것을 구현하는 데 뛰어나다. 명확한 아키텍처 문서가 주어지면 AI 에이전트는 전체 애플리케이션을 스캐폴딩하고, 모듈 전반에 걸쳐 일관된 패턴을 생성하며, 새 코드가 기존 관례를 따르도록 할 수 있다. 개발자의 역할은 보일러플레이트를 작성하는 일에서 보일러플레이트가 구현할 구조적 결정을 내리고 문서화하는 일로 이동한다.
구현
현대 코딩 에이전트는 자연어 설명에서 전체 기능을 생성하고, 복잡한 알고리즘을 구현하며, 서로 맞물려 작동하는 다중 파일 변경을 만들어낼 수 있다. 생산성 향상은 실제로 존재한다. 산업 조사에 따르면 생산성 향상은 25-39% 수준이며, 일부 작업에서는 더 큰 향상이 나타난다.
하지만 헤드라인 숫자가 말하는 것보다 그림은 더 미묘하다. METR의 한 연구에서는 AI 어시스턴트를 사용하는 숙련 개발자가 특정 작업에서 오히려 19% 더 오래 걸렸다고 밝혔다. 주된 이유는 AI 출력물을 검증하고, 디버깅하고, 수정하는 데 시간이 들었기 때문이다. AI는 구현 작업을 없애기보다 그것을 작성에서 검토, 안내, 검증으로 바꾼다.
테스트와 품질 보증
AI가 생성한 코드를 테스트하려면 에이전트가 무엇을 만들었는지뿐 아니라 어떻게 거기에 도달했는지도 평가해야 한다. 출력 평가는 최종 산출물을 확인한다. 코드가 컴파일되는가, 테스트가 통과하는가? 궤적 평가는 도구 호출과 중간 추론의 전체 순서를 확인한다. 둘 다 필요하다. 검증 단계를 건너뛴 유창한 출력은 눈에 보이는 오류보다 더 위험한 실패이기 때문이다.
AI는 테스트 생성 자체도 바꾼다. 에이전트는 인간이 생각하지 못했을 수 있는 엣지 케이스와 속성 기반 테스트를 포함한 테스트 케이스를 생성할 수 있다. 더 중요한 것은 테스트와 eval이 AI 에이전트에게 의도를 전달하는 주된 메커니즘이 된다는 점이다. 잘 작성된 eval 스위트는 “올바름”이 무엇인지 AI에게 알려주고, 그것을 검증하는 자동화된 방법을 제공한다.
이러한 실천은 지속적 품질 플라이휠에 연결될 때 가장 효과적이다. 벤치마크 스위트에 대해 평가하고, 실패를 근본 원인별로 클러스터링해 진단하고, 원인이 된 프롬프트나 도구를 최적화하고, 회귀 스위트에 대해 수정 사항을 검증하고, 프로덕션 트래픽에서 새로운 실패 모드를 모니터링한다. 각 주기는 누적 효과를 만든다.
코드 리뷰와 배포
리뷰 프로세스 자체도 강화되고 있다. AI는 인간 리뷰어가 코드를 보기 전에 잠재적 버그, 스타일 위반, 보안 취약점, 성능 문제를 찾아내는 1차 리뷰어 역할을 할 수 있다. 이것이 인간 리뷰를 대체하지는 않는다. 설계, 유지보수성, 전략적 정렬에 관한 맥락 의존적 결정은 여전히 인간 판단을 필요로 하기 때문이다. 하지만 리뷰어의 인지 부담은 크게 줄어든다.
배포 파이프라인 역시 AI를 인식하는 방향으로 바뀌고 있다. AI 에이전트는 배포 상태를 모니터링하고, 문제가 있는 릴리스를 자동으로 롤백하며, 변경의 성격과 범위를 바탕으로 배포 위험을 예측할 수 있다. 현대 배포 플랫폼은 AI 기반 관측 가능성과 점점 더 통합되어 프로덕션 동작과 개발 결정 사이에 피드백 루프를 만든다.
이 시리즈의 Day 5는 에이전트 산출물로 PR 규모가 커질 때 인간 리뷰어에게 무엇이 달라지는지를 다룬다. 번들 요약, 조건부 LGTM, 에이전트 기반 코드 리뷰 스킬 등이 포함된다.
유지보수와 진화
가장 과소평가되는 변화는 어쩌면 유지보수에 있다. 한때 새 팀원이 접근하기 어려웠던 레거시 코드베이스도 이제 AI 지원을 통해 탐색하고, 이해하고, 수정할 수 있다. AI 에이전트는 코드베이스를 읽고, 그 패턴을 이해하고, 변경에 필요한 관련 파일을 찾아내며, 기존 아키텍처를 존중하면서 수정사항을 구현할 수 있다.
이는 기술 부채에 큰 함의를 가진다. 원 작성자만 이해하기 때문에 “건드리기 너무 위험하다”고 여겨지던 코드를 이제는 더 안전하게 리팩터링하고, 현대화하고, 확장할 수 있다. AI 에이전트는 코드베이스를 프레임워크 간에 체계적으로 마이그레이션하고, 폐기된 API를 업데이트하고, 테스트 스위트를 현대화할 수 있다. 예전에는 너무 지루하고 위험해서 사실상 진행되지 않았던 작업들이다.
공장 모델: 소프트웨어를 만드는 시스템을 만든다
이러한 변화를 하나로 묶는 사고 모델을 우리는 공장 모델이라고 부른다. 이 모델에서 개발자의 주된 산출물은 코드가 아니라 코드를 생산하는 시스템이다. 이 시스템에는 다음이 포함된다.
· 무엇을 만들어야 하는지 정의하는 명세와 컨텍스트
· 명세를 구현으로 번역하는 에이전트
· 정확성을 검증하는 테스트와 품질 게이트
· 실패를 에이전트에게 다시 보내 수정하게 하는 피드백 루프
· 에이전트를 안전하고 예측 가능한 행동으로 제한하는 가드레일
공장 관리자는 모든 부품을 손으로 조립하지 않는다. 그는 조립 라인을 설계하고 품질 관리를 보장한다. 현대 개발자는 개발 시스템을 설계하고 그 산출물이 요구 기준을 충족하는지 보장한다. 성공은 에이전트에게 단계별 지시를 주는 데서가 아니라 성공 기준을 주고 반복하게 하는 데서 나온다.
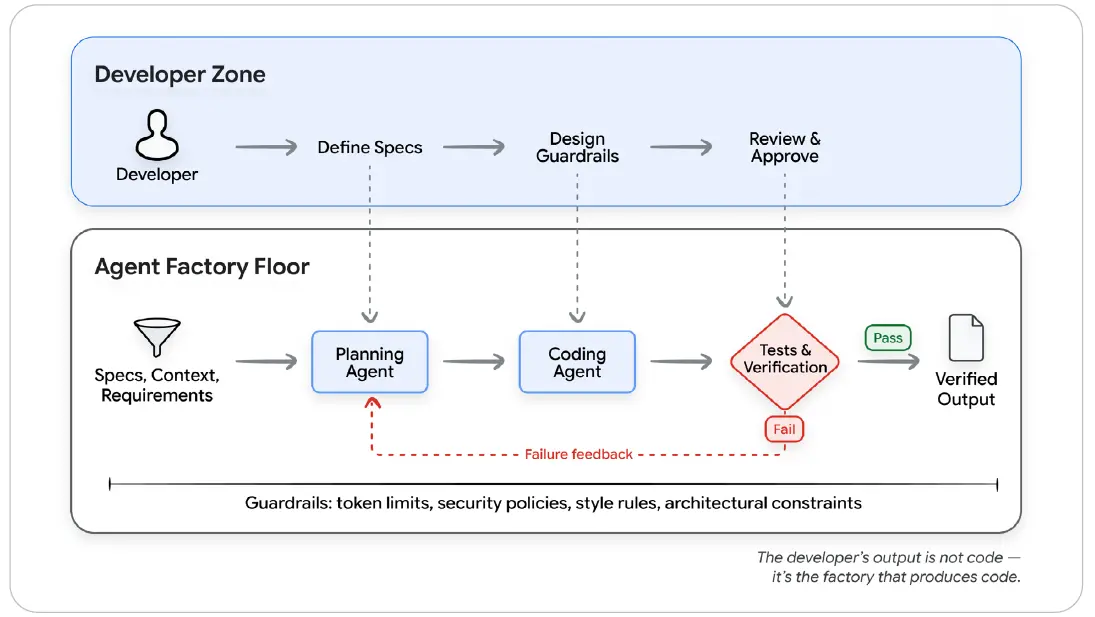
그림 6: 공장 모델
개발자는 시스템을 설계하고, 에이전트는 코드를 생산하며, 테스트는 출력을 검증한다. 개발자 영역에서는 명세 정의, 가드레일 설계, 리뷰와 승인이 이루어지고, 에이전트 공장 현장에서는 계획 에이전트와 코딩 에이전트가 테스트와 검증 루프를 통과하며 산출물을 만든다.
이 모델은 이 글의 나머지 부분을 이끄는 질문을 제기한다. 공장의 중심 기계는 무엇인가? 조립 라인 안에서 실제 일을 하는 에이전트 자체는 어떤 모습인가?
개발자가 공장 관리자라면, AI 모델은 공장 현장의 원시 엔진에 불과하다. 엔진만으로는 자동차를 만들 수 없다. 벨트, 기어, 안전 센서, 조립 라인이 필요하다. AI 보조 개발의 맥락에서 이 주변 장치를 하네스라고 부른다.
하네스 엔지니어링: 모델을 둘러싼 것
빌더가 AI 에이전트를 다루기 시작할 때 모델을 곧 시스템으로 여기는 유혹이 있다. 새 모델이 나오면 에이전트가 더 똑똑해지고, 오래된 모델을 쓰면 에이전트가 나빠진다고 생각한다. 모델이 좋고 나쁨의 모든 설명이 되는 것이다.
이 직관은 틀렸고, 잘못된 투자로 이어진다. 모델은 실행 중인 에이전트에 들어가는 하나의 입력일 뿐이다. 그 밖의 모든 것, 즉 프롬프트, 도구, 컨텍스트 정책, 훅, 샌드박스, 서브 에이전트, 관측 가능성이 하네스다. 하네스는 모델을 둘러싸고 모델이 실제로 무언가를 끝낼 수 있게 해주는 발판이다.
유용한 등식은 다음과 같다.
에이전트 = 모델 + 하네스
원시 모델은 에이전트가 아니다. 하네스가 상태, 도구 실행, 피드백 루프, 강제 가능한 제약을 부여할 때 비로소 에이전트가 된다. 개발자가 Claude Code, Cursor, Codex, Antigravity, Aider, Cline을 사용할 때 경험하는 동작은 밑에 어떤 모델이 있느냐만큼이나, 아니 그보다 더, 하네스가 무엇을 하느냐에 의해 좌우된다.
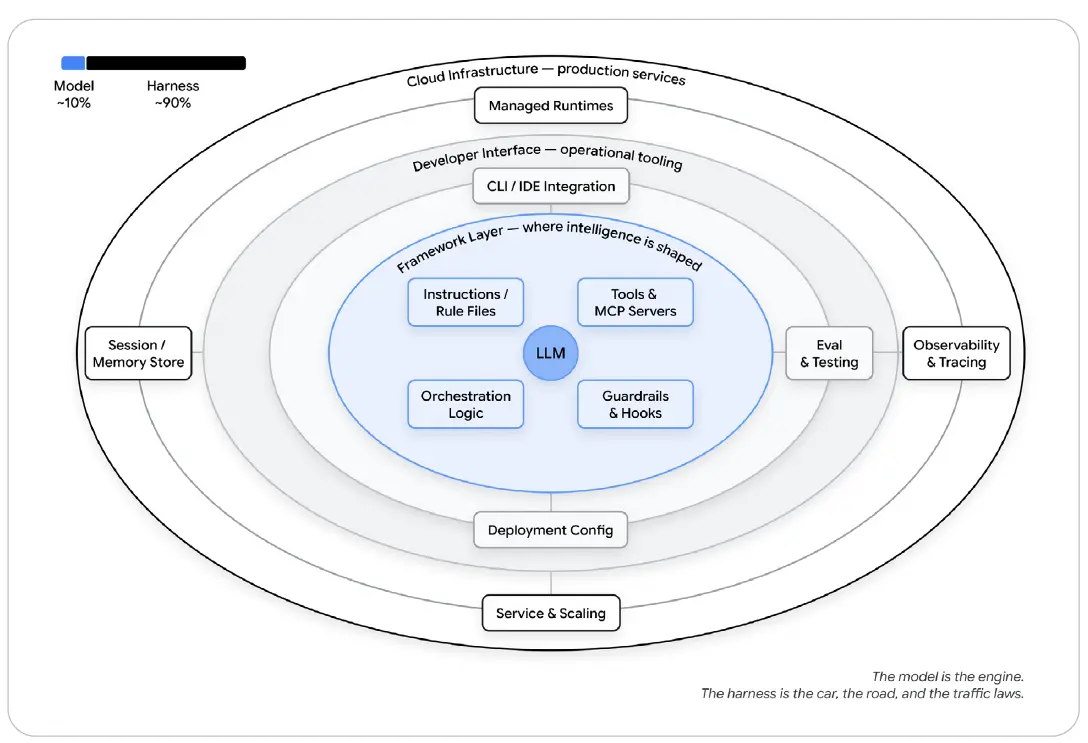
그림 7: 하네스의 해부 - 에이전트 = 모델 + 하네스
이 그림은 LLM이 중심에 있지만, 그 주변에 지시사항과 규칙 파일, 도구와 MCP 서버, 오케스트레이션 로직, 가드레일과 훅이 있고, 더 바깥에는 CLI/IDE 통합, 평가와 테스트, 관측 가능성, 세션/메모리 저장소, 배포 설정, 서비스와 스케일링, 관리형 런타임이 둘러싸고 있음을 보여준다. 핵심 메시지는 모델이 엔진이고 하네스가 자동차, 도로, 교통 법규라는 점이다.
하네스에는 무엇이 포함되는가
구체적으로 하네스에는 다음이 포함된다.
· 지시사항과 규칙 파일: 에이전트가 누구인지, 무엇을 중시하는지, 무엇을 해서는 안 되는지를 정의하는 텍스트. AGENTS.md, CLAUDE.md, GEMINI.md, 스킬 파일, 서브 에이전트 프롬프트가 포함된다.
· 도구: 에이전트가 호출할 수 있는 함수, MCP 서버, API와 더불어, 모델이 언제 어떻게 그것들을 호출해야 하는지 알려주는 설명 문구.
· 샌드박스와 실행 환경: 에이전트의 코드가 실제로 실행되는 곳, 접근할 수 있는 것과 접근할 수 없는 것을 정의하는 환경.
· 오케스트레이션 로직: 서브 에이전트 생성, 모델 라우팅, 전문가 간 핸드오프, 각 전문가가 언제 작동하는지 결정하는 규칙.
· 가드레일 또는 훅: 도구 호출 전, 파일 편집 후, 커밋 전 등 특정 생명주기 지점에서 실행되는 결정론적 코드. 훅은 에이전트가 결코 잊어서는 안 되지만 자주 잊는 것들을 처리하는 장소다.
· 관측 가능성: 로그, 추적, 평가, 비용과 지연 시간 측정. 관측 가능성이 없으면 에이전트가 잘하고 있는지, 아니면 조용히 빗나가고 있는지 알 방법이 없다.
이것이 꽤 넓은 표면적처럼 들린다면 실제로도 그렇다. 그리고 이것은 모델 제공자의 표면적이 아니라 팀의 표면적이다.
SDLC 안의 하네스
모델 자체는 작업을 어떻게 수행할지 결정하지만, 하네스는 이를 실행하는 데 필요한 도구, 샌드박스, 오케스트레이션에 접근하게 해주는 발판이다. 따라서 AI 에이전트가 작동하는 모든 단계에는 이 하네스가 존재해야 한다.
새로운 SDLC의 각 단계에서 하네스가 어떻게 작동하는지 살펴보자.
1. 요구사항, 계획, 아키텍처: 하네스 설정
이 단계에서는 하네스를 구성하고 보정한다. AI가 프로덕션 코드를 쓰기 전에 개발자는 에이전트 환경을 설정해야 한다.
· 하네스 설정: 하네스가 로드하여 모델에 제공할 지시사항과 규칙 파일을 제공한다. 예를 들어 AGENTS.md를 만들고 아키텍처 제약을 정의한다.
· 행동: 개발자는 에이전트가 접근할 도구, 예를 들어 특정 API나 데이터베이스 스키마를 정의하고, 에이전트가 깨뜨려서는 안 되는 기본 규칙을 설정한다.
2. 구현: 하네스 실행
활발한 코딩 중에는 하네스가 AI 모델을 집중되고, 안전하며, 생산적으로 유지하는 경계 역할을 한다.
· 사용되는 하네스 구성 요소: 샌드박스, 실행 환경, 도구.
· 행동: 모델이 코드를 생성할 때, 그 코드는 하네스의 격리된 샌드박스 안에서 실행된다. 모델이 파일을 읽거나 웹을 검색해야 한다면, 하네스가 제공한 도구를 사용한다.
3. 테스트와 QA: 피드백 루프
에이전트형 워크플로의 테스트는 자율적 자기교정을 가능하게 하기 위해 하네스에 크게 의존한다.
· 사용되는 하네스 구성 요소: 오케스트레이션 로직과 가드레일.
· 행동: 에이전트가 함수를 작성하면 하네스는 자동화된 테스트를 실행할 수 있는 실행 환경, 예를 들어 샌드박스 터미널을 제공한다. 테스트가 실패하면 오케스트레이션 로직이 그 환경에서 나온 오류 출력을 캡처하여 모델로 다시 보내고, 다시 시도하도록 요청한다. 하네스가 바로 이 자동화된 “생각 -> 행동 -> 관찰” 루프를 만든다.
4. 코드 리뷰, 배포, 유지보수: 하네스 관찰
코드가 작성된 뒤에도 하네스는 라이브 또는 준라이브 환경에서 에이전트가 안전하게 행동하도록 보장한다.
· 사용되는 하네스 구성 요소: 훅과 관측 가능성.
· 행동: 하네스는 결정론적 훅을 실행한다. 예를 들어 에이전트가 하드코딩된 비밀번호를 푸시하려고 하면 커밋을 막는다. 또한 관측 가능성 계층은 토큰 비용, 지연 시간, 에이전트 드리프트를 추적하여 인간 엔지니어가 에이전트가 왜 특정 배포 결정을 내렸는지 정확히 감사할 수 있게 한다.
바이브 코딩에서 에이전트형 엔지니어링으로의 전환은 단순히 어떤 도구를 쓰느냐의 문제가 아니다. 개발자는 같은 에이전트를 사용하면서도 바이브 코딩을 할 수도 있고 에이전트형 엔지니어링을 적용할 수도 있다. 차이를 만드는 것은 하네스를 얼마나 의도적으로 설정하고 적용하느냐다. 바이브 코딩은 빠른 구현을 목표로 하는 최소한의 또는 암묵적 발판에 의존한다. 에이전트형 엔지니어링은 첫 계획 문서부터 프로덕션 모니터링까지 AI를 안내하는 명확하고 광범위한 하네스 추상화에 의존한다.
이러한 의도적 설정의 효과는 매우 측정 가능하다. 공개 벤치마크는 하네스 효과의 크기를 구체적으로 보여준다. Terminal Bench 2.0에서 한 팀은 모델을 전혀 바꾸지 않고 하네스만 바꿔 코딩 에이전트를 Top 30 밖에서 Top 5로 끌어올렸다. LangChain의 별도 연구에서도 고정된 모델 주변의 시스템 프롬프트, 도구, 미들웨어만 조정해 같은 벤치마크 점수를 13.7점 높였다.
AI를 SDLC 전반에 도입하는 팀에게 이 관찰의 일상적 버전은 매우 중요하다. 에이전트가 잘못된 행동을 하면 첫 번째 본능은 모델을 탓하는 것이다. 그러나 실패는 더 자주 누락된 도구, 모호한 규칙, 없는 가드레일, 잡음으로 가득 찬 컨텍스트 윈도우에서 비롯된다. 정직하게 들여다보면 대부분의 에이전트 실패는 설정 실패다.
개발자 역할의 진화: 지휘자와 오케스트레이터
AI가 구현 작업을 더 많이 맡으면서 개발자의 역할은 흥미롭지만 동시에 방향 감각을 흔들 수 있는 방식으로 바뀌고 있다. 우리는 개발자가 유동적으로 오가는 두 가지 모드로 생각하는 것이 유용하다고 본다. 하나는 지휘자, 다른 하나는 오케스트레이터다.
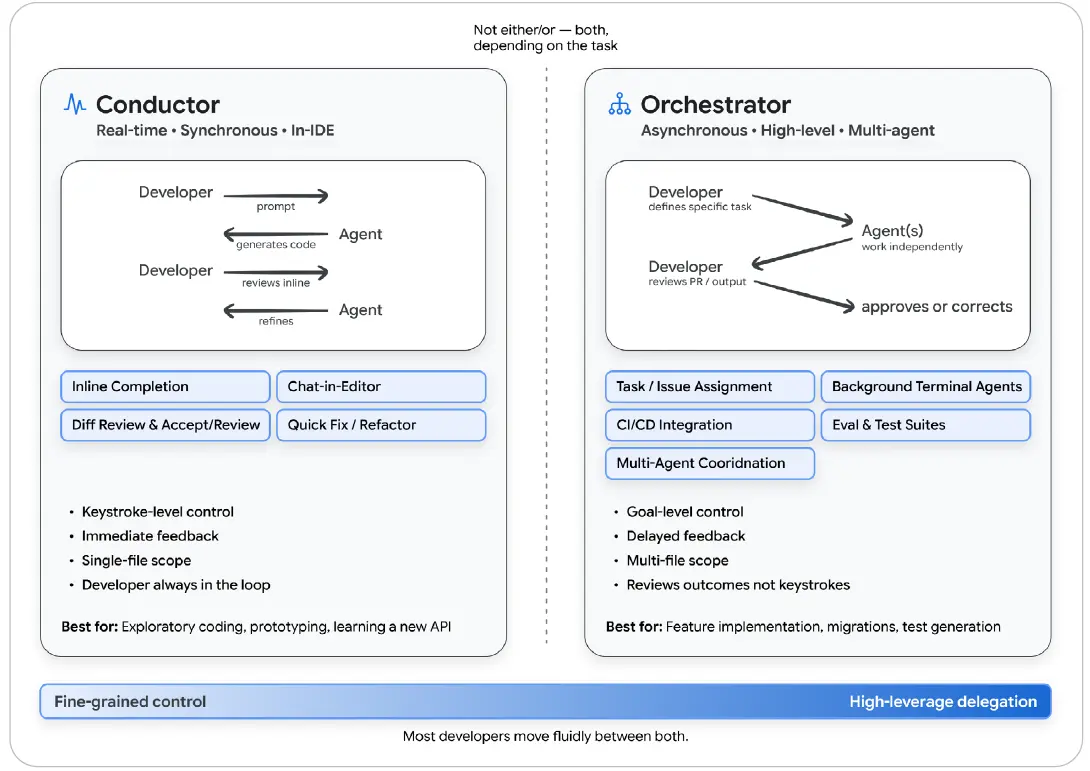
그림 8: 지휘자와 오케스트레이터 - AI 에이전트와 일하는 두 가지 모드
지휘자 모드는 실시간, 동기식, IDE 중심이다. 개발자가 프롬프트를 주고, 에이전트가 코드를 생성하고, 개발자가 인라인으로 검토하고 다듬는다. 오케스트레이터 모드는 비동기식, 고수준, 다중 에이전트 중심이다. 개발자가 특정 작업을 정의하면 에이전트들이 독립적으로 작업하고, 개발자는 PR이나 출력을 검토해 승인하거나 수정한다.
지휘자: 실시간 직접 지시
지휘자 모드에서 개발자는 AI 페어 프로그래머와 실시간으로 함께 일한다. IDE 안에서 코드가 나타나는 것을 보고, 프롬프트와 수정 지시로 AI를 이끌며, 무엇이 작성되는지에 대한 세밀한 통제를 유지한다. AI는 강력한 악기지만, 개발자는 모든 움직임을 적극적으로 지휘한다.
이 모드는 복잡한 로직을 다룰 때, 까다로운 문제를 디버깅할 때, 또는 낯선 코드베이스에서 각 변경을 이해하며 진행해야 할 때 흔하다. GitHub Copilot, Google의 Gemini Code Assist, Cursor, Windsurf 같은 도구는 인라인 완성, 채팅 인터페이스, 제자리 편집 기능을 통해 주로 이 모드를 지원한다.
지휘자 모드는 전통적인 엔지니어링 배경을 가진 개발자에게 자연스럽다. 많은 엔지니어가 중요하게 여기는 이해와 통제의 감각을 보존하기 때문이다. 위험은 이 모드가 병목이 될 수 있다는 점이다. 개발자가 모든 키 입력을 직접 지시한다면 AI가 제공하는 처리량 향상은 제한된다.
오케스트레이터: 비동기식 다중 에이전트 위임
오케스트레이터 모드에서 개발자는 더 높은 추상화 수준에서 일한다. 목표를 정의하고, 그것을 에이전트에 할당하고, 결과를 검토한다. 그러나 코드가 한 줄씩 나타나는 것을 지켜보지는 않는다. 에이전트들은 백그라운드에서 병렬로 코드베이스의 다른 부분을 작업할 수 있다. 개발자는 주기적으로 확인하고, 출력을 검토하고, 방향을 수정한다.
이 모드는 이미 확립된 패턴에 맞춘 버그 수정, 기능 구현, 코드베이스 마이그레이션, 테스트 생성처럼 잘 정의된 작업에 흔하다. Google의 Jules, GitHub Copilot의 에이전트 모드, Cursor의 백그라운드 에이전트, Claude Code 같은 도구는 비동기 작업 실행을 통해 이 모드를 지원한다. 이들은 종종 저장소, 빌드 도구, 테스트 스위트에 완전한 접근권을 가진 샌드박스 환경에서 작업한다.
오케스트레이터 모드는 다른 종류의 역량을 요구한다. 문법과 언어 관용구에 대한 깊은 전문성 대신 다음 능력을 강하게 요구한다.
· 명세화: 에이전트가 모호함 없이 실행할 수 있을 만큼 작업을 정확히 정의하는 능력.
· 분해: 큰 작업을 에이전트 실행에 알맞은 크기의 단위로 나누는 능력.
· 평가: 에이전트 출력이 품질 기준을 충족하는지 빠르게 판단하는 능력.
· 시스템 설계: 에이전트를 생산적으로 유지하는 제약, 테스트, 피드백 루프를 설계하는 능력.
80% 문제
AI 보조 개발에서 지속적으로 나타나는 도전 과제를 우리는 80% 문제라고 부른다. AI 에이전트는 기능을 위한 코드의 약 80%를 매우 빠르게 생성할 수 있지만, 나머지 20%, 즉 엣지 케이스, 오류 처리, 통합 지점, 미묘한 정확성 요구사항은 현재 모델이 자주 부족해하는 깊은 맥락 지식을 요구한다.
AI 오류의 성격은 단순한 문법 실수에서 더 교묘한 개념적 실패로 진화했다. 비즈니스 로직에 대한 잘못된 가정, 모호한 요구사항에 대해 명확화를 요청하지 않는 문제, 누락된 엣지 케이스, 장기 유지보수에 미묘한 부담을 만드는 아키텍처 결정이 여기에 포함된다. 이런 오류는 코드가 “그럴듯해 보이고” 기본 테스트까지 통과할 수 있기 때문에 오히려 더 탐지하기 어렵다.
이 문제를 가장 잘 다루는 개발자는 특정한 태도를 취한다. AI가 잘하는 것, 즉 잘 명세된 작업의 빠른 구현에는 AI를 사용한다. 반면 AI가 어려워하는 것, 즉 모호한 요구사항, 아키텍처 트레이드오프, 정확성 검증에는 자신의 주의를 남겨둔다. 그들은 AI가 만든 모든 것을 받아들여 더 빨라지려 하지 않는다. 자신의 전문성을 가장 중요한 곳에 집중함으로써 더 빨라지려 한다.
이 80% 문제를 효과적으로 다루려면 작업 단계에 맞는 도구를 적용해야 한다. 지휘자로 일하는 개발자에게 필요한 도구 세트는 오케스트레이터로 일하는 개발자에게 필요한 도구 세트와 다르다. 이러한 운영 모드를 일상 워크플로에 매핑하려면 현재 AI 에이전트 지형을 자율성과 통합 수준에 따라 분류할 필요가 있다.
실제 현장의 코딩 에이전트
오늘날 에이전트를 만드는 개발자는 대부분의 작업을 터미널에서 수행한다. 자연어로 대화하는 경우가 많고, 타이핑은 다른 코딩 에이전트가 담당하는 경우도 많다. 이것은 새로운 현상이다. 1년 전 같은 작업은 프레임워크, SDK, 클라우드 콘솔을 의미했다. 이제 그것들을 대체한 패턴에는 이름을 붙일 가치가 있다. 코딩 에이전트를 일상에 활용하려는 개발자에게도, 자기만의 에이전트를 만들려는 개발자에게도 그렇다.
개발자의 하루 속 코딩 에이전트
코딩 에이전트는 일상 업무에서 세 곳에 나타난다. 대부분의 개발자는 세 가지를 동시에 사용한다.
에디터 안에서: 개발자가 타이핑하는 동안 다음 줄을 제안하는 인라인 완성. 코드를 제자리에서 설명하거나 수정하는 채팅 패널. IDE 안에서의 전체 코드베이스 인식. 대부분의 사람이 처음 코딩 AI를 만나는 곳이며, 작업 흐름이 끊기지 않는 곳이다. 예로는 GitHub Copilot, Cursor, Windsurf, JetBrains AI Assistant가 있다.
터미널 안에서: 개발자가 명령줄에서 실행하고, 자연어로 목표를 넘긴 뒤, 코드베이스 전반에 걸쳐 작업하게 하는 코딩 에이전트. 전체 파일 시스템 접근, 다중 파일 편집, 도구와 테스트를 실행하고 결과에 따라 반복하는 능력이 있다. 오늘날 진지한 바이브 코딩은 주로 여기서 일어난다. 예로는 Antigravity CLI, Claude Code, Codex CLI, Open Code, Cline이 있다.
백그라운드에서: 작업을 받아 클라우드 호스팅 샌드박스에서 자율적으로 실행되는 에이전트. 종종 몇 시간 동안 작동하고, 결과물로 풀 리퀘스트를 만든다. 개발자는 작업을 맡기고 나중에 검토한다. 예로는 Google Jules, GitHub Copilot 에이전트 모드, Cursor의 백그라운드 에이전트, 고급 알고리즘 설계를 위한 Google의 특화 에이전트 AlphaEvolve가 있다.
실제로 에디터 에이전트는 개발자가 코드를 작성하는 흐름 중간에 제안, 빠른 수정, 설명을 원할 때 유용하다. 터미널 에이전트는 다중 파일 작업, 낯선 코드베이스 탐색, 에이전트가 코드를 실행하고 관찰 결과에 반응해야 하는 작업에 맞다. 백그라운드 에이전트는 개발자가 한 문단으로 설명하고 자리를 비울 수 있는 잘 명세된 작업, 예를 들어 알려진 버그 수정, 테스트 스위트 생성, 한 프레임워크에서 다른 프레임워크로 코드 마이그레이션하는 작업에 잘 맞다. 같은 개발자가 하루 안에 세 가지를 모두 사용하는 경우가 많다.
올바른 출발점은 작업에 따라 달라진다. 어느 범주가 자율성 사다리에서 더 높이 놓여 있느냐에 따라 결정되는 것이 아니다.
바이브 코딩으로 프로덕션 준비 에이전트 만들기
지금까지의 논의는 모두 코딩 에이전트를 사용해 소프트웨어를 만드는 일에 관한 것이었다. 기능 작성, 버그 수정, 테스트 생성, 코드 리팩터링이 그 예다. 그런데 만들어야 하는 대상 자체가 에이전트라면 어떻게 될까?
환불 요청을 처리하는 고객 지원 봇. 출처를 교차 확인해 근거 있는 보고서를 만드는 리서치 어시스턴트. 컴플라이언스를 모니터링하고 이상 징후를 표시하는 내부 도구. 이런 것들은 터미널의 코딩 에이전트만으로 해결하는 작업이 아니다. 자체 도구, 자체 메모리, 자체 평가, 자체 배포 인프라가 필요한 제품이다.
프로토타입 스크립트를 만들어내던 같은 터미널 기반 워크플로가 이제 이런 프로덕션 에이전트까지 도달한다. 실제 규모로 실행되고, 영속 메모리, 거버넌스, 관측 가능성을 갖춘 진짜 에이전트를 구축하고, 평가하고, 배포하는 일이 프레임워크와 클라우드 콘솔 작업에서 개발자가 이미 사용하던 같은 터미널과 같은 코딩 에이전트에게 말하는 작업으로 이동했다.
이 워크플로는 빌더가 실제 사용자에게 안정적으로 작동하는 에이전트를 필요로 할 때 중요하다. 세션을 넘어 유지되는 영속 메모리, 도구와 데이터에 대한 범위 지정 권한, 배포 전 회귀를 잡아내는 eval 커버리지, 에이전트가 실제로 무엇을 했는지 추적하는 관측 가능성이 필요하기 때문이다. 일회성 스크립트나 개인 자동화라면 일반 코딩 에이전트로 충분하다. 그 경우 에이전트가 목적지다. 실제 사용자에게 규모 있게 제공되는 에이전트라면 에이전트가 제품이며, 그 아래에 기반(substrate)이 필요하다.
Google의 Agents CLI는 이 아이디어를 중심으로 만들어졌다. Google Cloud에서 에이전트를 만들기 위한 스킬 세트를 묶은 작은 명령줄 도구이며, 중요한 점은 개발자가 선호하는 어떤 코딩 에이전트, 예를 들어 Claude Code, Codex 또는 다른 에이전트와도 함께 작동한다는 것이다. 한 번 설치한 뒤에는 코딩 에이전트가 전체 ADK 생명주기를 포괄하는 일곱 가지 새 스킬을 얻는다. 프로젝트 스캐폴딩, 에이전트 코드 작성, 평가, Agent Runtime 배포, 관측 가능성 연결이 여기에 포함된다. 개발자는 새 SDK를 배울 필요가 없다. 원하는 것을 설명하면 코딩 에이전트가 각 단계에서 적절한 스킬을 사용한다.
구체적으로 전체 빌드-평가-배포 루프는 다음과 같다.
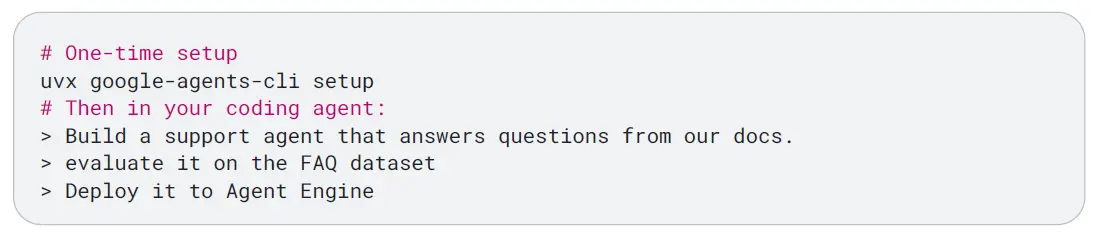 스니펫 1: Agents CLI 설정과 빌드
스니펫 1: Agents CLI 설정과 빌드
1회 설정
uvx google-agents-cli setup
그런 다음 코딩 에이전트에서:
우리 문서를 바탕으로 질문에 답하는 지원 에이전트를 만들어 줘.
FAQ 데이터셋으로 평가해 줘.
Agent Engine에 배포해 줘.
이 단일 지시 뒤에서 코딩 에이전트는 템플릿으로 프로젝트를 스캐폴딩하고, ADK 코드를 작성하고, evalset을 생성하고, 그것을 에이전트에 대해 실행하고, Agent Runtime에 배포하고, 결과를 보고한다. 직접 주도하기를 선호하는 개발자라면 같은 작업을 일반 CLI 명령으로도 수행할 수 있다. 예를 들면 agents-cli create, agents-cli playground, agents-cli eval, agents-cli deploy가 있다.
프로덕션 에이전트는 과거에 프로토타입과 별도의 스택과 별도의 워크플로를 요구했다. 이제 어제 개발자 노트북에서 실행되던 프로토타입은 재작성 없이도 오늘 실제 사용자에게 서비스를 제공하는 프로덕션 에이전트가 될 수 있다.
같은 워크플로는 하나의 에이전트에서 많은 에이전트로 확장된다. ADK는 그래프 기반 워크플로, 협업 에이전트를 구축하기 위한 다중 에이전트 워크플로, 공유 세션 상태, LLM 기반 위임, 명시적 호출 같은 상호작용 메커니즘을 제공하며, 이 요소들이 문제에 맞는 어떤 다중 에이전트 패턴으로도 결합된다.
에이전트 간 조정은 단순한 경우 공유 세션 상태를 통해, 도구 접근은 Model Context Protocol(MCP)을 통해, 에이전트 간 위임은 Agent2Agent(A2A) 프로토콜을 통해 이루어진다. Anthropic의 엔지니어링 팀은 2026년 초 이러한 아키텍처에서 실행되는 에이전트 팀이 2주 동안 Rust로 작동하는 C 컴파일러를 만들었다는 실험을 공개했다. 인간은 방향을 설정하고 출력을 검토했지만 구현을 직접 작성하지 않았다. 병목은 코드를 작성하는 데서 무엇을 해야 하는지 명세하고 에이전트들이 실제로 해냈는지 검증하는 데로 이동했다.
빌더에게 실무적 함의는 단순하다. 오늘 스크립트를 만들어내는 같은 바이브 코딩 워크플로가 내일 프로덕션 에이전트를 만들어낸다. 생명주기, 즉 빌드, 평가, 배포, 관찰, 개선이 한곳에 있다. 아이디어에서 실행 중인 에이전트까지의 경로는 몇 주에서 몇 시간으로 줄었고, 대부분의 작업은 이제 자연어 안에서 일어난다.
이 워크플로를 팀 규모에서 프로덕션 등급으로 만드는 실천, 즉 명세 주도 개발, 구조화된 코드 리뷰, 가드레일, 샌드박싱, 제로 트러스트 개발은 Day 5 동반 문서인 Spec-Driven Production Grade Development in the Age of Vibe Coding에서 다룬다.
AI 개발의 경제학
AI가 소프트웨어 개발 생명주기에 미치는 영향을 평가할 때 대화는 흔히 개발자 속도에서 시작해 거기서 끝난다. 코드를 얼마나 빨리 쓸 수 있는가? 그러나 엔지니어링 리더에게 더 중요한 지표는 총소유비용(TCO)이다.
AI 보조 개발의 진정한 비용을 이해하려면 서로 다른 워크플로가 자본지출(CapEx), 즉 무언가를 만들기 위한 초기 투자와 운영지출(OpEx), 즉 그것을 운영하고 고치고 유지하는 지속 비용 사이에서 재무적·운영적 부담을 어떻게 이동시키는지 살펴봐야 한다. 특히 AI 시대의 OpEx는 토큰 경제에 크게 좌우된다.
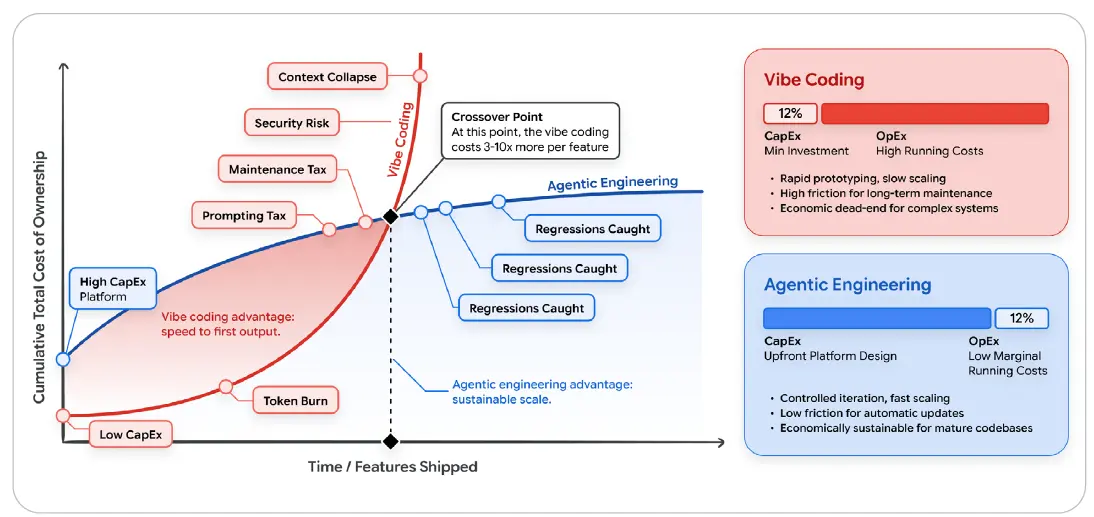 그림 9: AI 개발의 경제학
그림 9: AI 개발의 경제학
이 그림은 바이브 코딩이 낮은 초기 투자로 빠른 출발을 제공하지만 시간이 지날수록 토큰 소모, 프롬프팅 세금, 유지보수 세금, 보안 위험, 컨텍스트 붕괴로 총소유비용이 급격히 증가할 수 있음을 보여준다. 반대로 에이전트형 엔지니어링은 초기 플랫폼 설계 비용이 높지만 회귀를 잡아내고 반복을 통제해 장기적인 한계 비용을 낮춘다.
바이브 코딩의 숨은 부채: 낮은 CapEx, 높은 OpEx
처음 보면 바이브 코딩은 매우 비용 효율적으로 보인다. 진입 장벽은 사실상 0에 가깝다. AI 어시스턴트의 표준 월 구독과 몇 개의 느슨한 프롬프트만 있으면 된다. 개발자가 시스템 설계에 시간을 투자하기보다 모델의 기본 역량에 전적으로 의존하기 때문에 CapEx는 거의 없다.
하지만 바이브 코딩의 경제성은 거대하고 누적되는 OpEx 부담을 숨긴다.
· 토큰 소모율: LLM과의 모든 상호작용에는 입력 토큰과 출력 토큰에 기반한 비용이 든다. 바이브 코딩에서 개발자는 거대하고 구조화되지 않은 파일을 컨텍스트 창에 통째로 넣고, 모델이 만든 검증되지 않은 실수를 고치라고 반복해서 요청하는 경우가 많다. 이는 1차 성공률이 낮은 비싼 “프롬프팅 루프”를 만들고 API 토큰을 태운다.
· 유지보수 세금: 즉흥적 프롬프팅으로 작성된 코드는 구조적 일관성이 부족한 경우가 많다. 6개월 뒤 버그가 발생하면 인간 엔지니어가 구조화되지 않은 AI 생성 “스파게티” 코드를 역공학하는 데 며칠을 써야 할 수 있다.
· 보안 수정 비용: 자동화된 평가 하네스가 없으면 코드의 빠른 생성은 취약점의 빠른 생성으로 이어진다. 프로덕션에서 보안 결함을 고치는 비용은 설계 단계에서 잡아내는 비용보다 기하급수적으로 높다.
에이전트형 엔지니어링이라는 투자: 높은 CapEx, 낮은 OpEx
에이전트형 엔지니어링은 이 경제 모델을 뒤집는다. 프로덕션 코드 한 줄이 생성되기 전에 의도적이고 선행적인 엔지니어링 시간과 자원 투자가 필요하다.
에이전트형 엔지니어링의 CapEx에는 API 스키마 설계, 결정론적 테스트 스위트 구축, 그리고 무엇보다 에이전트의 컨텍스트 구조화가 포함된다. 이 초기 비용은 더 높지만 기능을 배포하고 유지하는 한계 비용은 극적으로 낮아진다. AI가 엄격하게 관리되는 “공장” 안에서 작동하기 때문에 출력은 구조적으로 건전하고, 사전 테스트되며, 회사 표준과 정렬된다.
재무적 지렛대로서의 컨텍스트 엔지니어링
토큰 경제에서 컨텍스트 엔지니어링은 단지 기술적 역량이 아니라 재무 전략이다. LLM은 전달되는 모든 정보 조각에 비용을 부과한다. 매 프롬프트마다 100,000토큰 규모의 저장소 전체를 보내는 방식은 규모 있게 운영할 수 없다.
효과적인 컨텍스트 엔지니어링은 모델이 넓고 시끄러운 페이로드가 아니라 정밀한 AGENTS.md 파일과 아키텍처 가드레일 같은 밀도 높고 신호가 강한 페이로드를 받도록 보장한다. 올바른 컨텍스트를 처음부터 제공하면 개발자는 에이전트의 1차 성공률을 크게 높여, 바이브 코딩을 괴롭히는 비싼 시행착오 루프를 피할 수 있다.
동적 컨텍스트와 스킬을 통한 효율 확장
OpEx를 진정으로 최적화하기 위해 고급 에이전트형 엔지니어링은 스킬 또는 Model Context Protocol 서버 같은 도구 호출을 통한 동적 컨텍스트에 의존한다. 이는 Day 3 문서에서 자세히 다룬다.
지능형 모델 라우팅
또한 에이전트형 엔지니어링은 지능형 모델 라우팅을 가능하게 한다. 바이브 코딩 워크플로에서 개발자는 보통 모든 상호작용에 하나의 거대한 프런티어 모델을 사용한다. 오타를 고치거나 기본 단위 테스트를 생성하는 일에도 프리미엄 토큰 가격을 지불하는 것이다.
잘 설계된 공장 모델은 이 낭비를 피한다. 요구사항, 아키텍처, 초기 구현처럼 복잡도가 높은 작업에는 크고 고급 모델을 사용한다. 하지만 테스트 생성, 코드 리뷰, CI/CD 모니터링처럼 결정론적이고 복잡도가 낮은 작업은 더 작고 빠르며 훨씬 저렴한 모델로 자동 라우팅한다. 다중 모델 생태계를 오케스트레이션함으로써 엔지니어링 팀은 최고 수준의 출력 품질을 유지하면서 운영 토큰 비용을 체계적으로 낮출 수 있다.
어디서 시작할 것인가
문법에서 의도로의 전환은 미래 상태가 아니다. 그것은 오늘 우리 앞에 놓인 일이다. 개인 빌더로서 이 글을 읽든, 팀이나 조직이 이러한 도구를 어떻게 도입해야 할지 고민하는 리더로서 읽든, 같은 기본 원칙이 적용된다. AI는 자신이 들어간 엔지니어링 문화를 증폭한다. 아래 실천들은 이 원칙을 행동으로 옮긴 것이다.
개인 개발자를 위해
1. 프로젝트에 AGENTS.md 또는 이에 준하는 파일을 설정하라. 선택한 코딩 에이전트에 맞는 관례를 고른다. 스택, 관례, 절대 규칙, 워크플로를 담은 열 줄로 시작하라. 에이전트가 다시는 하지 말아야 할 일을 할 때마다 규칙을 하나씩 추가하라.
2. 코딩 에이전트에 스킬 세트를 설치하라. 예를 들어 Agents CLI 같은 도구를 사용해 에이전트를 빌드하고, 평가하고, 배포하고, 최적화하는 스킬을 갖추게 하라.
3. 반복되는 워크플로 하나를 골라 첫 번째 에이전트로 만들라. 리서치 워크플로, 코드 리뷰 프로세스, 반복 보고서, 정기적으로 만드는 콘텐츠가 될 수 있다. 프로토타입에는 코딩 에이전트를 사용하고, 그 가치가 입증되면 Agents CLI를 통해 프로덕션 에이전트로 발전시켜라. 에이전트 하나를 끝까지 만들어보는 경험은 수백 개의 설명을 읽는 것보다 더 많은 것을 가르친다.
4. 코드를 생성하기 전에 테스트와 eval을 작성하라. 둘은 AI와 맺는 계약이다. 잘 작성된 테스트와 eval 스위트는 어떤 자연어 프롬프트보다 의도를 더 정확히 전달하며, AI 보조 개발을 바이브 코딩에서 에이전트형 엔지니어링으로 바꾼다.
5. 배포될 에이전트 산출물의 모든 줄을 검토하라. 영리해 보이는 것은 의심하라. 임포트가 실제 패키지인지 확인하라. 오류 처리가 현실적인 실패 모드를 다루는지 검증하라. 팀이 이해하지 못하는 코드는 팀이 감당할 수 없는 디버깅 비용이 된다.
6. 개발자 역량을 계속 유지하라. AI는 개발자가 더 도전적인 일에 집중할 수 있도록 일상적 작업을 처리한다. 이 구조가 작동하려면 디버깅, 시스템 설계, 성능과 정확성에 대한 직관 같은 기초 역량이 날카롭게 유지되어야 한다. AI를 전문성을 대체하는 것이 아니라 전문성을 더 큰 규모로 적용하게 해주는 수단으로 다뤄라. 복잡한 디버깅, AI 출력에 대한 코드 리뷰, 아키텍처 토론을 정기적으로 연습하는 일은 엔지니어로 성장하는 데 여전히 필수다.
엔지니어링 리더를 위해
7. 컨텍스트 엔지니어링을 팀의 1급 엔지니어링 실천으로 만들라. AGENTS.md, 시스템 프롬프트, eval 스위트, 스킬 라이브러리를 코드처럼 다뤄라. 풀 리퀘스트로 리뷰하고, 프로젝트와 함께 버전 관리하고, 책임자를 지정하라. 이 규율이 없으면 하네스는 드리프트하고 에이전트 행동은 팀 전반에서 재현 불가능해진다.
8. 데모가 아니라 eval에서 기준을 세워라. 작동하는 데모는 에이전트가 한 번 성공할 수 있음을 증명한다. 통과하는 eval 스위트는 에이전트가 안정적으로 성공한다는 것을 증명한다. 그러나 명확한 루브릭 없는 eval은 아무것도 측정하지 못한다. 무엇을 채점하는지 정의하라. 작업 성공, 도구 사용 품질, 궤적 준수, 환각, 응답 품질 등이 될 수 있다. 공유 워크플로로 에이전트를 출시하기 전에 명시적 루브릭을 갖춘 eval 커버리지를 필수 조건으로 요구하라. 이는 서비스 배포에 테스트 커버리지를 게이트로 두는 것과 같다.
9. AI 생성 코드에 맞게 코드 리뷰를 재구성하라. AI 생성 코드는 인간이 작성한 코드와 같거나 더 높은 수준의 검토를 요구한다. 특히 환각된 의존성, 부실한 오류 처리, 얼핏 보면 맞아 보이지만 미묘한 정확성 격차를 만드는 부분에 더 주의를 기울여야 한다. 생성 코드의 실패 모드에 대해 리뷰어를 훈련하고, 리뷰 체크리스트를 그에 맞게 조정하라.
팀 규범에서 프로토타이핑 작업과 프로덕션 작업을 구분하라. 바이브 코딩은 탐색에 맞는 속도다. 에이전트형 엔지니어링은 프로덕션에 맞는 규율이다. 어느 프로젝트, 어느 브랜치, 어느 환경에서 어떤 작업 모드가 필요한지 경계를 명시하라. 이 구분을 흐릿하게 유지하는 팀은 프로토타입을 우연히 배포하게 된다.
하네스 구성 요소를 공유 팀 자산으로 투자하라. 재사용 가능한 시스템 프롬프트, 스킬 라이브러리, MCP 서버 연결, 평가 하네스는 프로젝트를 넘어 복리로 가치를 만든다. 그것들을 인프라로 다뤄라. 문서화하고, 유지하고, 의도적으로 개선하라. AI 보조 개발에서 가장 큰 복리 효과를 얻는 팀은 하네스를 한 번 만들고 여러 번 다듬는 팀이다.
조직을 위해
AI 보조 개발을 생산성 기능이 아니라 엔지니어링 투자로 다뤄라. 가장 큰 성과를 내는 팀은 AI 도구를 eval 커버리지, 관측 가능성, 명확한 아키텍처 표준과 결합한다. 그런 발판 없이 코딩 에이전트를 배포하면 품질 없는 속도만 생기며, 이는 어떤 팀도 갚기 어려울 만큼 빠르게 기술 부채로 누적된다.
규모를 키우기 전에 프로덕션 기반을 투자하라. 노트북에서 실행되는 바이브 코딩 프로토타입은 프로덕션 시스템이 아니다. 하나가 다른 하나로 승격되는 것은 그 주변의 운영 규율 때문이다. CI에서 실행되는 궤적 평가와 최종 응답 평가, 모든 에이전트 실행에 대한 추적, 에이전트별 범위 지정 권한, 생성 코드의 실패 모드에 맞춘 보안 리뷰가 필요하다. 첫 프로덕션 에이전트가 배포된 뒤가 아니라 그 전에 이 기반을 구축하라.
도구와 에이전트 간 통신에 개방형 표준을 채택하라. 도구 접근을 위한 Model Context Protocol(MCP)과 에이전트 간 위임을 위한 Agent2Agent(A2A)는 다중 에이전트 시스템의 결합 조직으로 수렴하고 있다. 지금 이를 선택하면 벤더와 프레임워크를 섞어 쓸 수 있는 선택지를 유지하고, 나중에 플랫폼을 다시 갈아엎는 일을 피할 수 있다.
인간만의 팀이나 에이전트만의 워크플로가 아니라 인간과 에이전트의 하이브리드 팀을 계획하라. 지난 1년 동안 가장 강력한 프로덕션 결과는 인간이 방향을 설정하고, 에이전트가 구현하며, 명확한 핸드오프 프로토콜이 그 경계를 관리하는 아키텍처에서 나왔다. 코드 리뷰 프로세스, 온콜 로테이션, 팀 구조는 이제 에이전트가 단순한 도구가 아니라 참여자라는 사실을 반영하도록 진화해야 한다.
채용과 역량 개발의 초점을 구현만이 아니라 판단으로 재정의하라. 구현이 더 빠르고 자동화될수록 병목은 명세화, 평가, 아키텍처 판단, 리뷰로 이동한다. 이러한 역량을 의도적으로 채용하고 개발하라. 앞으로 몇 년 동안 가장 가치 있는 엔지니어는 가장 많은 코드를 쓰는 사람이 아니라 에이전트를 잘 지휘하고 위임할 수 있는 사람일 것이다.
결론: 새로운 인터페이스로서의 의도
문법에서 의도로의 전환은 미래 예측이 아니라 현재 현실이다. 개발자들은 이미 어떻게 만들지 지정하는 시간보다 무엇을 원하는지 설명하는 데 더 많은 시간을 쓰고 있다. SDLC는 이미 AI 역량을 중심으로 압축되고, 재구성되고, 다시 상상되고 있다. 질문은 이 변화가 일어날지 여부가 아니라 개인 개발자, 팀, 조직이 이 변화를 얼마나 효과적으로 헤쳐 나갈 것인가다.
이 글에서 제시한 프레임워크, 즉 바이브 코딩에서 에이전트형 엔지니어링으로 이어지는 스펙트럼, 개발자 역할에 관한 지휘자-오케스트레이터 모델, 에이전트 유형의 분류, 소프트웨어 생산에 관한 공장 모델은 빠르게 변하는 지형을 이해하기 위한 사고 모델이다. 구체적인 도구와 역량이 바뀌더라도 이 모델들은 계속 유용할 것이다.
세 가지 원칙은 오래 지속될 것이다.
구조는 확장되지만 바이브는 확장되지 않는다. 바이브 코딩은 탐색, 프로토타이핑, 개인 프로젝트에는 유효한 접근이다. 하지만 조직이 의존하는 소프트웨어에는 에이전트형 엔지니어링의 규율, 즉 명세, 테스트, 가드레일, 아키텍처에 대한 인간 감독이 선택 사항이 아니다. “작동하는 것처럼 보인다”와 “모든 조건에서 올바르게 작동한다” 사이의 간극에는 프로덕션 장애, 보안 취약점, 유지보수 악몽이 존재한다.
AI는 당신의 엔지니어링 문화를 증폭한다. 강한 테스트 관행, 명확한 아키텍처 표준, 건강한 코드 리뷰 프로세스를 가진 조직은 그렇지 않은 조직보다 AI 보조 개발에서 훨씬 더 큰 가치를 얻는다. AI는 힘의 배율기다. 그리고 그것은 강점과 약점을 모두 배가한다.
인간의 역할은 줄어드는 것이 아니라 진화하고 있다. 아키텍처를 이해하고, 정확한 명세를 정의하고, 출력을 비판적으로 평가하고, 효과적인 제약과 피드백 루프 시스템을 설계할 수 있는 빌더는 그 어느 때보다 가치 있다. 중요한 역량은 구현에서 판단으로, 코드 작성에서 코드를 생산하는 시스템 설계로 이동하고 있다.
우리는 소프트웨어가 만들어지는 방식뿐 아니라 어떤 종류의 소프트웨어를 만들 수 있는지까지 바꿀 변화의 출발점에 서 있다. 더 작은 팀이 더 큰 문제를 다룰 수 있게 될 것이다. 개인 개발자는 예전에는 부서 전체가 필요했던 시스템을 만들고 유지할 수 있게 될 것이다. 소프트웨어 창작의 장벽은 계속 낮아져, 소프트웨어 개발이라는 실천은 더 넓은 사람들에게 열릴 것이다.
성공할 팀은 AI를 강력한 도구로 받아들이면서도 신뢰할 수 있는 소프트웨어의 토대였던 엔지니어링 규율을 유지하는 팀이다. 그들은 소프트웨어 엔지니어링의 미래가 인간 전문성과 AI 역량 중 하나를 선택하는 데 있지 않음을 이해할 것이다. 미래는 둘이 각자의 고유한 강점을 기여할 수 있는 시스템을 설계하는 데 있다.
생성은 해결되었다. 검증, 판단, 방향 설정이 새로운 장인정신이다.
주석
GetPanto, “AI Coding Assistant Statistics 2025-2026,” https://www.getpanto.ai/blog/ai-coding-assistant-statistics; Index.dev, “Developer Productivity Statistics with AI Tools,” https://www.index.dev/blog/developer-productivity-statistics-with-ai-tools
Karpathy, A., “Vibe Coding,” X/Twitter post, February 2025. https://x.com/karpathy/status/1886192184808149383; Wikipedia, “Vibe coding,” https://en.wikipedia.org/wiki/Vibe_coding
Osmani, A., “Agentic Engineering,” https://addyosmani.com/blog/agentic-engineering/
Karpathy, A., “From Vibe Coding to Agentic Engineering,” 2026; The New Stack, “Vibe Coding is Passe,” https://thenewstack.io/vibe-coding-is-passe/
Glide Blog, “What is Agentic Engineering?” https://www.glideapps.com/blog/what-is-agentic-engineering; The New Stack, “Vibe Coding, Agentic Engineering,” https://thenewstack.io/vibe-coding-agentic-engineering/
CircleCI, “AI-Native SDLC,” https://circleci.com/blog/ai-sdlc/
GroovyWeb, “SDLC in the AI Era: Software Development 2026,” https://www.groovyweb.co/blog/sdlc-ai-era-software-development-2026; EPAM, “From Traditional Software to a Native AI SDLC,” https://www.epam.com/about/newsroom/in-the-news/2026/from-traditional-software-to-a-native-ai-sdlc-how-genai-is-redefining-engineering
Osmani, A., “The Factory Model,” https://addyosmani.com/blog/factory-model/
Deloitte, “AI in Software Engineering: Productivity Gains 2025-2026,” projecting 30-35% gains across the full development process.
METR, “Uplift Update: Measuring the Impact of AI Coding Tools,” February 2026, https://metr.org/blog/2026-02-24-uplift-update/
Google, “Introduction to Agents,” Agents Whitepaper Series, November 2025.
Osmani, A., “From Conductors to Orchestrators: The Future of Agentic Coding,” https://addyosmani.com/blog/future-agentic-coding/
Google, “Jules: AI-Powered Coding Agent,” https://developers.googleblog.com/en/the-next-chapter-of-the-gemini-era-for-developers/
Osmani, A., “The 80% Problem in Agentic Coding,” https://addyo.substack.com/p/the-80-problem-in-agentic-coding
Medium, Dave Patten, “The State of AI Coding Agents 2026: From Pair Programming to Autonomous AI Teams,” https://medium.com/@dave-patten/the-state-of-ai-coding-agents-2026-from-pair-programming-to-autonomous-ai-teams-b11f2b39232a
Lawfare, “When the Vibes Are Off: The Security Risks of AI-Generated Code,” https://www.lawfaremedia.org/article/when-the-vibe-are-off--the-security-risks-of-ai-generated-code
Google, “Introduction to Agents,” Multi-Agent Systems and Design Patterns section, November 2025.
Google, “Agent Development Kit (ADK),” https://google.github.io/adk-docs/; Kartakis, S., “From Zero to Multi-Agents: A Beginner’s Guide to Google Agent Development Kit (ADK),” https://medium.com/@sokratis.kartakis/from-zero-to-multi-agents-a-beginners-guide-to-google-agent-development-kit-adk-b56e9b5f7861
Google, “Agent-to-Agent (A2A) Protocol,” https://google.github.io/a2a-protocol/; Kartakis, S. and Hotz, H., “Generative AI in the Real World: Understanding A2A,” O’Reilly Podcast, https://www.oreilly.com/radar/podcast/generative-ai-in-the-real-world-understanding-a2a-with-heiko-hotz-and-sokratis-kartakis/
TLDL, “AI Coding Tools 2026,” https://www.tldl.io/resources/ai-coding-tools-2026; Kanerika, “GitHub Copilot vs Claude Code vs Cursor vs Windsurf,” https://kanerika.com/blogs/github-copilot-vs-claude-code-vs-cursor-vs-windsurf/
Google, “Gemini Code Assist,” https://cloud.google.com/gemini/docs/codeassist/overview
Dark Reading, “Coders Adopt AI Agents, but Security Pitfalls Lurk in 2026,” https://www.darkreading.com/application-security/coders-adopt-ai-agents-security-pitfalls-lurk-2026
Google, “Gemini CLI,” https://github.com/google-gemini/gemini-cli.
Google, “Agent Tools: Interoperability with Model Context Protocol (MCP),” Agents Whitepaper Series, November 2025.
Google, “Agent Quality” and “Prototype to Production,” Agents Whitepaper Series, November 2025.
Lawfare, “When the Vibes Are Off: The Security Risks of AI-Generated Code,” https://www.lawfaremedia.org/article/when-the-vibe-are-off--the-security-risks-of-ai-generated-code
DevOps.com, “AI-Generated Code Packages Can Lead to Slopsquatting Threat,” https://devops.com/ai-generated-code-packages-can-lead-to-slopsquatting-threat/
Osmani, A., “Beyond Vibe Coding,” O’Reilly Media, 2025-2026, https://www.oreilly.com/library/view/beyond-vibe-coding/9798341634749/
“Awesome LLM Apps,” https://github.com/Shubhamsaboo/awesome-llm-apps
Osmani, A., “My LLM Coding Workflow Going Into 2026,” https://addyosmani.com/blog/ai-coding-workflow/
Questera, “7 AI Coding Trends to Watch in 2026,” https://www.questera.ai/blogs/7-ai-coding-trends-to-watch-in-2026
DEV Community, “Programming in the Age of AI: From Code to Intent,” https://dev.to/robertobutti/programming-in-the-age-of-ai-from-code-to-intent-46eo
댓글
GitHub 계정으로 의견을 남길 수 있습니다. 댓글은 GitHub Discussions에 저장됩니다.