2026년 5월 공개된 Agent Skills 백서의 한국어 완역본입니다.
저자: Tanvi Singhal, Gabriela Hernandez Larios, Debanshu Dus, Lavi Nigam, Smitha Kolan
이 글은 원문 PDF의 표지, 감사의 말, 목차, 1장부터 Appendix B, 그리고 Endnotes까지를 원문 순서에 맞춰 한국어로 옮긴 번역본입니다. 요약 재구성본이 아니라, 원문 흐름을 최대한 보존한 완역본에 가깝습니다.
먼저 읽을 핵심
- Agent Skill은 에이전트가 필요할 때만 불러오는 절차기억 폴더다.
SKILL.md를 중심으로scripts/,references/,assets/를 붙여 확장한다.- 긴 시스템 프롬프트보다 단일 에이전트 + Skill 라이브러리가 더 단순하고 운영하기 쉬운 경우가 많다.
- 좋은 Skill은 출력만이 아니라 트리거, 실행, 회귀, 토큰 예산까지 평가해야 한다.
- 장기 자산은 모델 자체보다, 조직의 판단을 쌓아 가는 Skill 라이브러리다.
이 글을 읽는 방법
- 빠르게 핵심만 잡고 싶다면: 1장, 3장, 4장, 5장, Appendix A
- 팀 운영 관점에서 읽고 싶다면: 4장, 5장, 7장, Appendix B
- 실제 Skill을 만들 생각이라면: 2장과 Appendix A를 함께 보는 편이 낫다
번역자 주
원문 용어는 가능한 한 자연스럽게 옮기되, 실무상 중요한 표현은 영문을 병기했습니다. 예를 들어 context rot, progressive disclosure, procedural memory 같은 용어는 한국어 번역만으로는 뉘앙스가 손실되기 쉬워 본문 안에 함께 남겼습니다.
원문 목차 펼쳐 보기
서론 ··· 원문 p.4
Agent Skill이란 무엇인가 - 그리고 첫 번째 Skill을 어떻게 만들 것인가 ··· 원문 p.6
Skill의 구조와 점진적 공개 ··· 원문 p.7
경로 A: 이미 알고 있는 것을 번역하기 ··· 원문 p.8
경로 B: 에이전트가 방금 한 일을 결정화하기 ··· 원문 p.9
직접 시험해 보기와 현재 Skill 설치 방식 ··· 원문 p.10
그런데 Skill은 MCP와 AGENTS.md와 어떻게 다른가? ··· 원문 p.11
Agent Skills는 왜 그토록 빠르게 인기를 얻었는가? ··· 원문 p.12
챗봇용인가, 코딩 에이전트용인가, 아니면 멀티 에이전트 엔터프라이즈 사례용인가? ··· 원문 p.13
Skill 평가하기 ··· 원문 p.15
평가 도구상자 ··· 원문 p.17
트리거는 첫 번째 관문이다 ··· 원문 p.18
출력 품질과 도구 호출 궤적 ··· 원문 p.19
시스템 vs. Skill: 평가의 착시 ··· 원문 p.21
토큰 예산: 고립 평가는 함정이다 ··· 원문 p.22
“평가 커버리지”란 무엇을 뜻하는가 ··· 원문 p.24
프로토타입에서 프로덕션으로 ··· 원문 p.25
실제 Agent Runtime 안에는 무엇이 들어 있는가 ··· 원문 p.27
왜 Skills가 개선의 단위인가 ··· 원문 p.28
데모를 깨뜨리는 실패 모드: 컨텍스트 오버플로 ··· 원문 p.29
이것이 토큰 예산에 의미하는 것 ··· 원문 p.31
메타 스킬과 자기 개선형 Skill에 대하여 ··· 원문 p.32
어디서 이 방식이 무너지는가 ··· 원문 p.34
이 흐름은 어디로 가고 있는가 ··· 원문 p.35
Skills 조합과 패키징 ··· 원문 p.36
실행 라우팅: DAG 오케스트레이션 ··· 원문 p.36
환경 패키징: Capability Profiles ··· 원문 p.37
그래프 채우기: 정식 Skill 분류 체계 ··· 원문 p.37
컨텍스트 부채와 지능의 앞단 이동 ··· 원문 p.38
아키텍처별 트레이드오프 ··· 원문 p.38
바로 적용할 수 있는 모범 사례 ··· 원문 p.39
이미 존재하는 수많은 Skill 중 무엇을 선택할 것인가 ··· 원문 p.39
결론 ··· 원문 p.41
Appendix A - 실무 치트시트 ··· 원문 p.43
Appendix B - 사례 연구: 코드로서의 도메인 전문성 ··· 원문 p.50
Endnotes ··· 원문 p.60
감사의 말
큐레이터 및 편집자: Shubham Saboo
디자이너: Michael Lanning
1. 서론
Agent Skills는 에이전트에게 지식과 회사 고유의 맥락을 갖추게 하는 방식이다. 하나의 Agent Skill은 SKILL.md 파일을 포함한 폴더이며, 여기에 scripts/, references/, assets/ 디렉터리가 함께 들어갈 수 있다. 2장에서 이 구조를 자세히 다룬다.
Agent Skills는 여러 플랫폼을 넘나들며 사용할 수 있는 이식성의 표준으로 자리 잡아가고 있다. 그렇다면 왜 이렇게 갑자기 빠른 속도로 채택되고 있을까? 우리는 Agent Skills가 AI 에이전트 개발에서 나타나는 네 가지 주요 마찰 지점을 해결하기 때문이라고 본다.
• 지시가 많아질수록 결과는 나빠진다. 생각나는 모든 지시사항을 하나의 시스템 프롬프트에 쏟아 넣으면, 결국 대규모 언어 모델, 즉 LLM의 성능은 저하된다. 이는 컨텍스트 로트(context rot), 곧 맥락이 길어지고 혼탁해지면서 모델의 처리 품질이 떨어지는 문제로 알려져 있다. Skills는 필요한 순간에만 로드되는 방식으로 이 문제를 해결한다. 5장에서는 이와 관련된 연구 배경을 풀어 본다.
Agent Skills는 범용 에이전트를 필요할 때마다 전문가로 바꿔준다. 컨텍스트 비대화 없이. 가볍고, 이식 가능하게.
• 무엇을 아는가를 넘어, 어떻게 하는가를 기억한다. LLM에는 이미 어떤 일이 있었는지를 기억하는 방식, 즉 일화기억(episodic memory)에 가까운 기능과, 사실을 기억하는 의미기억(semantic memory)에 해당하는 기능이 어느 정도 있다. 그러나 지금까지 부족했던 것은 일을 단계별로 수행하는 방법을 기억하는 능력, 즉 절차기억(procedural memory)이었다. 이런 점에서 Agent Skills는 LLM 에이전트를 위한 최초의 신뢰할 만한 절차기억 기본 단위로 볼 수 있다.
• 멀티 에이전트 과부하. 생태계는 구축과 유지보수가 어렵기로 악명 높은 복잡한 멀티 에이전트 시스템으로 넘쳐났다. 물론 특정 작업에는 여전히 멀티 에이전트 구조가 필요하다. 그러나 Skills를 사용하면 하나의 범용 에이전트가 여러 전문 역할로 자연스럽게 전환될 수 있다. 3장에서는 실제 사례와 함께 이 주장을 깊이 전개한다.
• 이식성. 마크다운 파일 하나를 담은 폴더라는 구조는 놀라울 만큼 가벼운 기본 구성 단위다. 파일 시스템에 접근할 수 있는 에이전트라면 누구나 이를 사용할 수 있으므로, 여러 벤더가 공존하는 AI 환경에서도 거의 완전한 이식성을 제공한다.
이 백서에서는 두 부류의 독자를 염두에 둔다. 첫째는 Skills를 사용하는 빌더(Builders)이고, 둘째는 Skills를 만들고, 버전을 관리하며, 운영하는 개발자(Developers)다. 먼저 2장과 3장에서는 Skill이 무엇이며 어떻게 사용하는지를 차근차근 살펴본다. 이후 4장부터 8장까지는 평가, 프로덕션 준비, 메타 스킬, 조합과 같은 보다 복잡한 개발자 주제로 들어간다.
성격이 급한 독자라면 Appendix A의 인쇄용 운영 치트시트를 참고하면 된다. Appendix B에서는 리테일 분야의 사례 연구를 단계별로 살펴본다.
2. Agent Skill이란 무엇인가 — 그리고 첫 번째 Skill을 어떻게 만들 것인가
Agent Skills는 범용 에이전트에게 필요할 때 호출되는 전문 역량을 부여하기 위한 기본 구성 단위다. 물론 Skill은 단 하나의 마크다운 파일처럼 단순할 수도 있다. 그러나 거기에서 멈출 필요는 없다. 그 뒤에 놓인 패러다임은 상당히 혁신적이다.
오늘날 Agent Skills는 크게 두 가지 뚜렷한 경로를 통해 등장하고 있다.
첫 번째 경로는 도메인 전문가가 주도한다. 이들은 이미 어딘가에 기록된 조직 지식을 가지고 있다. 예를 들어 30쪽짜리 운영 절차서를 갖고 있는 준법감시 담당자나, 신입 직원 온보딩 가이드를 갖고 있는 인사 관리자를 떠올려 보자. 이들이 Skill을 작성하고 사용하기 위해 코딩을 배울 필요는 없다. 이미 내용은 가지고 있다. 남은 일은 그 내용을 에이전트가 똑똑하게 사용할 수 있는 형식으로 바꾸는 것이다.
두 번째 경로는 개발자가 에이전트형 워크플로나 코드화된 워크플로를 Skill로 감싸는 방식이다. 에이전트가 단순하지 않고 반복 가능한 작업을 성공적으로 수행했다면, 다음번에도 같은 과정을 처음부터 다시 알아내게 만들고 싶지는 않을 것이다. 대신 그 성공적인 실행을 바탕으로 에이전트가 Skill을 만들게 하고 싶을 것이다. 요컨대 우리는 새로운 패턴을 목격하고 있다. 좋은 재사용 가능 워크플로는 무엇이든 Skill이 되며, 꼭 사람이 직접 작성할 필요도 없다. 에이전트가 작성하고, 사람은 검토한다. 이는 이미 메타 스킬의 영역에 들어선 이야기이며, 여기서는 가볍게 소개한 뒤 6장에서 더 깊이 다룬다.
두 집단이 만들어 내는 최종 산출물은 같다. 즉, SKILL.md라는 기본 구성 단위를 중심으로 한 Skill 폴더다. 다만 그곳에 도달하는 여정이 다를 뿐이다.
Skill의 구조와 점진적 공개
각 경로를 살펴보기 전에 먼저 Skill의 구조를 검토해 보자. 모든 Skill은 저마다의 디렉터리 안에 존재하며, 반드시 SKILL.md 파일을 포함해야 한다. agentskills.io의 공개 표준이 정의한 전체 정식 구조를 이해하기 위해, 실용적인 예시를 하나 보자.
아래는 매일 카페 준비 업무를 수행하도록 설계된 Skill 폴더의 예시다. 기억할 점은 하나다. 필수 파일은 SKILL.md뿐이며, 나머지는 선택 사항이다.
Snippet 1: cafe-preparation Skill의 표준 레이아웃과 점진적 공개 설계를 보여 주는 디렉터리 트리 구조.
cafe-preparation/
├── SKILL.md # 필수: 메타데이터 + 지침
├── scripts/ # 선택: 실행 가능한 코드(언어 제한 없음)
│ ├── calc_quantities.py # 라테, 크루아상 등의 예상 수량 계산
│ └── convert_to_ingredients.py # 음료와 베이커리 품목을 재료 단위로 변환
├── references/ # 선택: 보조 문맥 자료
│ ├── menu_and_recipes.md # 말차 라테: 파우더 3g, 우유 200ml…
│ └── minimums.md # 항상 최소 40잔의 라테 준비…
└── assets/ # 선택: 템플릿, 설정, 스키마
├── prep_sheet_template.md # 주방 직원용 최종 준비표 양식
└── shopping_list_template.md # 거래처 발주용 목록 양식
이 구조에서 혁신적인 부분은 점진적 공개다. Skills는 세 단계로 로드된다.
• 메타데이터, 즉 이름과 설명은 항상 에이전트의 컨텍스트 안에 들어 있다.
• SKILL.md 본문은 해당 Skill이 트리거될 때에만 로드된다.
• 함께 묶인 리소스는 엄격히 필요한 경우에만 로드된다. 또한 스크립트는 토큰 윈도우를 오염시키지 않고 실행된다.
이 말은 곧, 100개의 Skill을 설치해 두더라도 매 턴마다 지불하는 토큰 비용은 각 Skill의 작은 메타데이터 비용뿐이라는 뜻이다. 이제 실제로 어떻게 만들 수 있는지 살펴보자.
경로 A: 이미 알고 있는 것을 번역하기
최소한의 SKILL.md 템플릿은 Appendix A에 있다. 그대로 복사해 사용할 수 있다. 처음에 특히 집중해야 할 부분은 YAML 프런트매터다. 이것이 활성화 트리거이기 때문이다.
Snippet 2: cafe-preparation Skill을 위한 YAML 프런트매터 설정.
name: cafe-preparation
description: |
카페 운영을 위한 일일 재료 수요를 계산하고 준비 시트를 생성한다.
사용자가 일일 수량 산정, 음료를 재료 단위로 변환, 또는 쇼핑 목록 생성을
요청할 때 사용한다.
직원 교대 근무표 작성이나 재무 회계에는 사용하지 않는다.
처음부터 제대로 잡아야 할 것은 두 가지다. 이름 짓기와 description 필드다.
이름 짓기. 이름을 붙일 때는 명확하고 평범하게 하라. 디렉터리에는 bigquery_ingestion처럼 snake_case를 쓰고, Skill 이름에는 pdf-processing처럼 kebab-case를 사용하라. 또한 managing-databases처럼 동명사형을 선호하는 것이 좋다. utils나 tools처럼 지나치게 일반적인 이름은 피하고, 내부에서만 통하는 은어도 제외하라.
Description. 이 필드는 당신의 라우팅 알고리즘이다. 모델은 이 설명만 보고 Agent Skill을 로드할지 결정한다. 무엇을 하는지 명시하고, 트리거 키워드는 앞쪽에 배치하라. 모델이 Skill을 충분히 호출하지 않는다면 더 강하게 적어도 된다. 그리고 이 Skill이 어떤 용도에는 쓰이면 안 되는지도 명시적으로 적어야 한다.
SKILL.md 초안이 만들어졌다면, 그다음에는 폴더의 나머지 부분을 구성한다. 바로 여기서 점진적 공개의 장점이 드러나기 시작한다. SKILL.md 본문 안에 반드시 들어갈 필요가 없는 것은 다른 곳으로 보내면 된다.
· Scripts. 내보낸 파일 파싱, 수학 계산, 형식 변환처럼 결정론적으로 처리할 수 있는 작업은 scripts/에 둔다. 모델은 무엇을 해야 할지 결정하고, 스크립트는 무거운 실행 처리를 담당한다.
· References. Skill이 실제로 실행된 뒤에야 필요한 지식, 예를 들어 도메인 원칙, 정의, 경계 사례 처리 방식 등은 references/에 두고 필요할 때 로드한다.
· Assets. 템플릿과 스키마는 assets/에 둔다.
경험칙은 간단하다. SKILL.md가 길어지기 시작했다면, 다음 문단은 본문이 아니라 references/에 들어가야 할 가능성이 높다.
성격이 급한 독자라면 Appendix A의 인쇄용 운영 치트시트를 참고할 수 있다. 거기에는 초기 Skill 개발을 안내하는 선별된 해야 할 일과 하지 말아야 할 일이 정리되어 있다.[1]
경로 B: 에이전트가 방금 한 일을 결정화하기
두 번째 경로는 반대쪽에서 출발한다. 이미 가지고 있던 것을 변환하는 것이 아니라, 에이전트가 방금 수행한 일을 결정화하는 것이다.
에이전트가 어떤 작업을 성공적으로 완료했다. 그 워크플로가 재사용 가능하다는 사실을 당신이 알아차렸다. 이제 다음번에 비슷한 작업이 등장하면, 방금 배운 내용의 혜택을 받게 만들고 싶다.
이것이 바로 메타 스킬의 영역이다. 메타 스킬은 다른 Skill을 포착하거나 개선하는 것을 자기 역할로 삼는 Skill이다. Anthropic의 skill-creator[2], Nous Research의 Hermes Agent[3], awesome-llm-apps의 self-improving-agent-skills 패턴[4] 같은 도구들은 모두 이런 워크플로를 지원한다. 에이전트는 성공적인 실행 궤적을 관찰하고 SKILL.md 초안을 제안한다. 사람은 처음부터 작성하는 대신 검토한다.
품질 기준은 동일하게 적용된다. 검토와 반복 수정을 거친 에이전트 작성 Skill은 훌륭할 수 있다. 하지만 검토되지 않은 에이전트 작성 Skill은 Skill이 전혀 없는 것보다 더 나쁜 경우가 많다. 이 주제는 6장의 메타 스킬 부분에서 훨씬 더 깊이 다시 다룬다.
직접 시험해 보기와 현재 Skill 설치 방식
폴더가 준비되었다면, 사람이 직접 작성했든 에이전트가 초안을 만들었든, 이제 시험해 볼 차례다. 사용하는 도구가 요구하는 올바른 위치에 Skill 폴더를 넣고, 에이전트를 재시작한 뒤, 자연스러운 프롬프트로 테스트하라. 실행 추적을 확인해 Skill이 실제로 트리거되었는지 보라. 그런 다음 Skill이 트리거되면 안 되는 프롬프트도 넣어 보고, 조용히 머무는지 확인하라.
그렇다면 “올바른 위치”란 정확히 어디일까?
여기서 문제가 조금 미묘해진다. Skills의 인기가 폭발적으로 커지면서 생긴 단점 중 하나다. 모든 에이전트나 코딩 도구가 이 형식으로 수렴하고 있지만, 각 도구가 Skill을 찾는 위치는 조금씩 다르다. 현재 Skills를 설치하고 사용하는 방식은 크게 세 가지 패러다임으로 나눌 수 있다.
• 파일 드롭 — 코딩 에이전트와 CLI. 로컬 환경에서는 파일 기반 패턴이 일반적이다. 특정 숨김 디렉터리에 Skill 폴더를 넣거나 설치하면 에이전트가 이를 감지한다. 프로젝트 루트의 공유 .agents/skills/ 폴더를 둘러싼 반가운 교차 도구 관례가 등장하고 있기는 하지만, 여전히 많은 도구는 각자의 전용 경로를 사용한다. 팁을 하나 덧붙이자면, 여러 CLI 도구와 IDE를 오가며 사용한다면 skillport나 openskills 같은 커뮤니티 관리 도구가 중앙 Skill 라이브러리를 각 도구가 기대하는 위치로 자동 심볼릭 링크해 줄 수 있다.
• UI 설치 — 웹 및 엔터프라이즈 작업 공간. 웹 기반 협업 플랫폼이나 소비자용 AI 챗봇을 사용한다면, 터미널이나 숨김 폴더를 직접 만질 일이 거의 없다. 이런 플랫폼은 시각적 UI 레지스트리를 통해 Skill 폴더를 설치, 업로드, 관리할 수 있게 해 준다. 몇 번의 클릭만으로 가능하며, 팀 전체를 위한 라우팅은 뒤에서 처리된다.
• 프로그래밍 방식 경로 — 커스텀 프레임워크. Google Agent Development Kit처럼 직접 만든 비코딩 에이전트를 처음부터 구축하고 있다면, Skill을 프로그래밍 방식으로 로드한다. 코드에서 폴더 경로를 지정하는 식이다. 예를 들어 SkillToolset 클래스에 등록하면[5], 내부적으로 모델에 필요한 load_skill 라우팅 도구를 자동 생성할 수 있다.
전반적인 패턴은 어디서나 같다. Skill 폴더를 올바른 디렉터리에 넣고, 에이전트를 재시작하면 에이전트가 이를 인식한다. 도구마다 달라지는 것은 바로 그 “올바른 디렉터리”다.
조언을 하나 하자면, 추측하지 말고 사용하는 코딩 에이전트나 AI 챗봇의 문서를 확인하라. 형식은 공유되지만, 설치 경로, 활성화 규칙, 도구별 세부 사항은 다르다. 여기에는 allowed-tools 화이트리스트, 보안 게이트, 플러그인 번들링 같은 요소가 포함된다.
그런데 Skill은 MCP와 AGENTS.md와 어떻게 다른가?
Agent Skills의 아키텍처상 위치를 이해하려면 이 기본 단위들을 서로 대응시켜 보는 것이 도움이 된다.
Skill vs. MCP. 이 둘은 경쟁하지 않는다. 서로 조합된다. Model Context Protocol, 즉 MCP는 도달 범위에 관한 것이다. MCP 서버는 에이전트를 외부 시스템, 예를 들어 Drive, Salesforce, BigQuery, 또는 내부 API와 연결한다. 반면 Skill은 노하우에 관한 것이다. Skill은 에이전트에게 특정 종류의 작업을 어떻게 생각하고 수행해야 하는지 가르친다. Skill에 데이터가 필요할 때는 에이전트에게 도구를 호출하라고 지시한다. 그 도구는 대개 MCP 서버가 제공한다.
Skill vs. AGENTS.md. 한쪽에서 보면 AGENTS.md는 프로젝트 안에서 항상 로드된다. 반면 Skills는 필요할 때만 로드된다. 가장 깔끔한 구성은 둘 다 사용하는 것이다. AGENTS.md는 간결하게 유지하라. 프로젝트 관례, 기술 스택, 빌드 명령어 같은 전역 정보만 담는 것이 좋다. 필요하다면 AGENTS.md를 Skills 라이브러리로 들어가는 라우터처럼 사용할 수도 있다. 파일 아래쪽에 짧은 카탈로그를 두어, 에이전트에게 어떤 Skill을 사용할 수 있는지 알려 주는 방식이다.
3. Agent Skills는 왜 그토록 빠르게 인기를 얻었는가?
2025년 초라고 상상해 보자. 당신은 반복적인 백오피스 업무를 덜어 줄 시스템을 만들어 달라는 요청을 받았다. 업무에는 회사 스타일을 지키며 브리프를 바탕으로 슬라이드 덱을 생성하는 일, 구조화된 청구서 PDF를 파싱하는 일, 인사 온보딩 가이드를 초안 작성하는 일, 주간 컴플라이언스 보고서를 요약하는 일, 그리고 팀이 자동화할 새 업무를 계속 찾아내면서 필연적으로 늘어날 긴 꼬리의 유사 작업들이 포함된다.
아마도 당신은 자연스럽게 멀티 에이전트 아키텍처를 기본 선택지로 삼았을 것이다. 맨 위에는 라우터 에이전트가 있고, 그 아래에는 몇 개의 하위 전문 에이전트가 배치된다. 그리고 이후에는 CI/CD 파이프라인, 오케스트레이션 로직, 새 HR 하위 에이전트를 배포했을 때 청구서 처리 하위 에이전트가 깨지지 않도록 보장하는 일에 고통스러운 시간을 쏟게 되었을 것이다.
Agent Skills가 등장하면서 이 워크플로는 훨씬 단순해졌다. 바로 이 마찰이 Anthropic이 Skill 형식을 처음 만들게 된 배경이었다. PDF를 읽고 슬라이드를 만드는 초기 Skills[6]는 같은 일을 훨씬 더 가볍게 수행하는 방식을 보여 주었다. 이제는 라우터가 하위 에이전트들에게 작업을 분배하는 대신, 하나의 에이전트가 Skill 라이브러리를 갖는다. Skills는 명령어를 실행하고, MCP 서버를 호출하며, Python 스크립트를 함께 묶을 수 있다. 어떤 Skill을 언제 로드할지는 에이전트가 결정한다. 당신은 에이전트들을 유지보수하는 것이 아니라 Skills를 유지보수한다. 그 결과 운영 부담은 줄어들 수 있다.
분명히 해 두자. Agent Skills가 멀티 에이전트 아키텍처를 없애는 것은 아니다.
실제 병렬성이 필요할 때, 접근 권한이나 보안 태세나 외부 시스템이 달라지는 진짜 역량 경계가 있을 때, 추상화 계층이 실제로 서로 다른 계층적 분해가 필요할 때, 적대적 구성이나 견제와 균형 구조가 필요할 때, 하위 에이전트 간 통신이 필요할 때, 또는 서로 다른 모델을 조합해야 할 때는 여전히 멀티 에이전트가 정답이다. 이 목록이 모든 경우를 다 포괄하는 것은 아니다.
Skills가 한 일은 그동안 비어 있던 아키텍처 기본 단위를 도입한 것이다. 예전에는 기본적으로 멀티 에이전트로 구축되던 많은 시스템을 이제는 설계 단계에서부터 Skills를 갖춘 단일 에이전트 구조로 우아하게 단순화할 수 있다.
챗봇용인가, 코딩 에이전트용인가, 아니면 멀티 에이전트 엔터프라이즈 사례용인가?
처음 공개적으로 눈에 띈 Skills는 AI 챗봇 형태에 가까웠다. 그러나 코딩 에이전트라는 서사가 며칠 또는 몇 주 안에 뒤따라왔다. 그리고 그 순간 Skills는 폭발적으로 확산되었다. Skills는 바이브 코딩 열풍 한가운데에 정확히 떨어졌고, 개발자들이 기다려 온 형식임이 드러났다.
일부 멀티 에이전트형 아키텍처에서는 정의상 각 하위 에이전트가 이미 전문가다. 예를 들어 리서치 에이전트에는 별도의 리서치 Skill이 필요하지 않을 수 있다. Skills가 더 유용한 시나리오는 하나의 범용 에이전트가 설계상 여러 분야의 전문가로 유연하게 변신해야 하는 경우다. 다만 멀티 에이전트와 Skills가 잘 조합되는 경우도 있다. 예를 들어 각 전문 에이전트가 자기 역할 범위에 맞는 별도의 Skill 라이브러리를 가져야 하는 상황이 그럴 수 있다.
이제 물류 회사를 생각해 보자. 제품 유형, 도구, 경로 제약, 고객 SLA, 규제 구역 등에 따라 100개의 프로세스 변형이 존재한다. 이를 우아하고 가볍게 해결하려면 어떤 방식이 가능할까?
· 하나의 에이전트, 하나의 거대한 컨텍스트 윈도우. 이 방식은 즉각적인 컨텍스트 로트와 과도한 토큰 비용을 유발한다.
· 런북에 RAG를 적용하기. 아마 2년 전이었다면 이 방식이 적절한 답이었을 것이다. 하지만 이제는 벡터 DB, 임베딩 모델, 청킹 전략을 운영해야 한다. 게다가 그 청킹 품질은 실제 절차의 품질과는 별개의 문제다.
· 멀티 에이전트, 프로세스마다 하나의 하위 에이전트. 이 방식은 100개의 하위 에이전트를 만들고, 각각에 프로세스별 시스템 프롬프트를 부여하는 구조다. 결과적으로 100개의 배포, 100개의 평가 표면, 복잡한 라우팅 계층을 관리해야 하는 운영 악몽이 된다.
· 하나의 에이전트, 100개의 Skills. 이 경우에는 Skill 형식이 잘 맞는다. 같은 업무에 여러 변형이 존재하기 때문이다. Skills의 점진적 공개 구조 덕분에 100개의 Skills는 대략 100 × 50 tokens, 즉 약 5,000토큰 정도의 항상 로드되는 메타데이터 비용만 발생시킨다. 물류 요청에는 SKU, 출발지, 중량, 위험물 표시, SLA처럼 강한 활성화 단서가 포함된다. 그래서 Skill 설명을 날카롭게 작성할 수 있고, 선택도 신뢰할 만해진다. 절차는 버전 관리 안에 보관된다. 101번째 변형을 추가하는 일은 새로운 배포가 아니라 새 폴더 하나를 추가하는 일이 된다. 유지보수와 확장이 훨씬 쉬워진다.
하지만 가장 중요한 것은 언제나 엄격한 평가 과정을 갖추고, 서로 다른 방식의 성능을 비교한 뒤 최종 결정을 내려야 한다는 점이다. 4장에서는 바로 그 평가 작업이 실제로 어떤 모습인지 다룬다.
마음속에 적어 둘 만한 원칙이 하나 있다. 채택은 언제나 저항이 가장 적은 경로를 따른다. 문서를 쓸 수 있는 사람이라면 누구나 Skill을 쓸 수 있다. 이 점이 진입 장벽을 낮춘다. 그리고 위키, 런북, 엔지니어들의 머릿속에 잠재되어 있던 절차 지식은 마침내 흘러 들어갈 수 있는 구조화된 자리를 얻게 된다.
4. Skill 평가하기
이제 첫 번째 Skill이 생겼거나, 어쩌면 작은 Skill 라이브러리까지 갖추었을지도 모른다. 그렇다면 곧바로 따라오는 질문은 이것이다. 그 Skill들이 실제로 작동한다는 것을 어떻게 알 수 있는가? 이 장에서는 Skill이 어떻게 실패하는지, 어떻게 테스트해야 하는지, 그리고 어떤 Skill이 라이브러리에 들어갈 자격을 얻기 전에 반드시 통과해야 하는 네 가지 조건을 살펴본다.
테스트가 없는 Agent Skill은 역량이 아니라 희망사항일 뿐이다.
최근 연구자들이 SkillsBench 2025에서 실제 세계의 에이전트 작업 84개를 벤치마크했을 때[7], Skill을 사용했을 때 오히려 사용하지 않았을 때보다 성능이 나빠진 경우가 19%였다. 잘못 설계된 Skill은 단순한 중립적 소음이 아니었다. 그것들은 실제로 역량을 떨어뜨렸다. 다행히 이런 실패는 예측 가능하며, 네 가지 뚜렷한 모드로 나뉜다.
• 트리거 실패: 잘못된 Skill이 켜지거나, 올바른 Skill이 켜지지 않는다.
• 실행 실패: Skill은 올바르게 트리거되지만, 잘못된 출력이나 엉뚱한 도구 호출을 만든다.
• 토큰 예산 실패: 거대한 Skill 본문이 컨텍스트 윈도우를 밀어내어, 관련 없는 턴의 성능까지 떨어뜨린다.
• 회귀: 새로 추가된 Skill이 기존 Skill과 겹치면서, 이전에는 잘 작동하던 라우팅을 깨뜨린다.
트리거 실패는 라우팅 로그에서 드러난다. 실행 실패는 출력 품질에서 드러난다. 토큰 예산 실패는 현실적인 컨텍스트 부하 아래에서 드러난다. 회귀 실패는 전체 라이브러리를 함께 실행해 보아야만 드러난다.
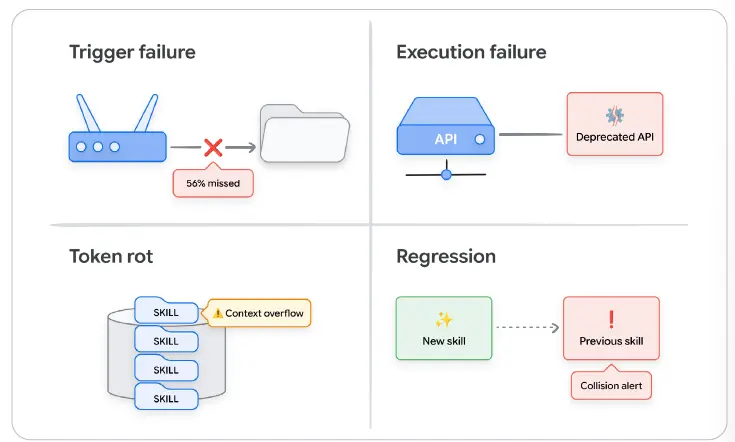
그림 1: 실패 모드가 어떻게 갈라지는지 보여 준다. 트리거 실패와 실행 실패는 단일 턴 수준에서 발생하는 반면, 토큰 예산 실패와 회귀 실패는 여러 Skill이 무거운 프로덕션 부하 아래에서 상호작용할 때에야 나타난다.
그림 내 주요 문구 번역: Trigger failure = 트리거 실패, Execution failure = 실행 실패, Token rot = 토큰 로트, Regression = 회귀, 56% missed = 56% 누락, Deprecated API = 폐기된 API, Context overflow = 컨텍스트 오버플로, Collision alert = 충돌 경고.
평가 도구상자
다섯 가지 상호 보완적인 테스트 패턴이 Agent Skills의 전체 실패 표면을 포괄한다.
| 패턴 | 설명 | 예시 | 다루는 실패 모드 | 필요한 시점 |
| Eval-as-Unit-Test | Skill 변경이 있을 때마다 CI에서 실행되는 Skill용 테스트 파일 | 세 개의 JSON 평가 케이스를 매 push마다 agenteval로 실행한다. 실패한 테스트는 병합을 막는다. |
전체 | 모든 Skill, 모든 변경 |
| Golden Dataset | Skill과 함께 저장되는, 선별되고 버전 관리된 입력·기대 출력 쌍 | 대표 질의 30개와 기대 도구 호출·출력 형식을 Skill 디렉터리에 커밋한다. | 실행, 트리거 | Draft 단계 이상 |
| LLM-as-Judge | 동료 모델이 루브릭에 따라 대규모로 출력을 평가한다 | 세 가지 루브릭 차원에 따라 참조 기반 점수를 매긴다. 순서 편향을 중화하기 위해 참조 출력과 실제 출력의 위치를 바꿔 두 번 실행한다. | 실행 | 읽기 전용 및 Draft |
| Adversarial / Red-Team | 실패 모드를 드러내도록 설계된 체계적 탐색 | 모든 긍정 트리거마다 하나의 재표현 사례와 하나의 부정 경계 사례를 만든다. agentregress는 회귀를 표시한다. |
트리거, 실행 | 실행 허용 단계로 승격하기 전 |
| Canary / Shadow Mode | 전체 출시 전, 통제된 트래픽에 배포한다 | Shadow는 오프라인 병렬 비교다. Canary는 실제 트래픽 1%를 24시간 동안 selftune으로 모니터링한다. |
회귀 | 각 실행 허용 릴리스 전 |
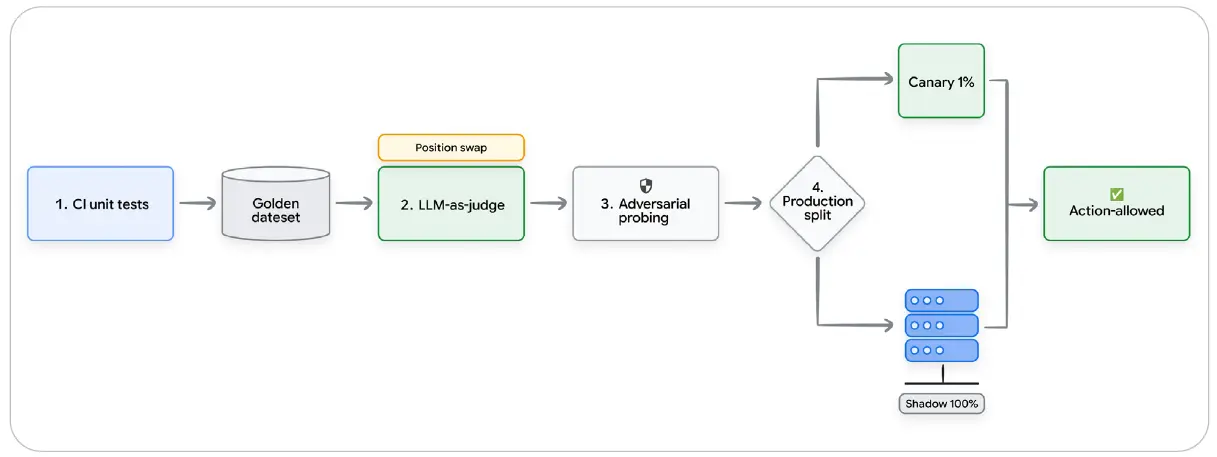
그림 2: 게이트키핑 메커니즘을 보여 준다. 메타데이터는 얇은 라우팅 계층처럼 작동하여, 특정 활성화 단서가 사용자 의도와 맞아떨어질 때까지 활성 토큰 수를 낮게 유지한다.
그림 내 주요 문구 번역: CI unit tests = CI 단위 테스트, Golden dataset = 골든 데이터셋, LLM-as-judge = LLM-as-Judge, Adversarial probing = 적대적 탐색, Production split = 프로덕션 분기, Canary 1% = 카나리 1%, Shadow 100% = 섀도 100%, Action-allowed = 실행 허용.
트리거는 첫 번째 관문이다
절대 켜지지 않는 Skill은 도움이 될 수 없다. 반대로 너무 넓게 켜지는 Skill은 관련 없는 컨텍스트를 주입한다.
Vercel의 프로덕션 분석[8]은 일관되게 활성화될 것으로 기대했던 Skill에서 56%의 비호출률이 드러났다고 보고했다. 더 중요하게는, 지침이 제거된 Skill은 58%의 점수를 얻은 반면, Skill이 없는 에이전트는 63%를 얻었다. 이 5점 차이는 잘못 설계된 Skill이 실제로 역량을 깎아먹을 수 있음을 보여 준다.
같은 연구에서 Vercel은 프로젝트 관례를 담은 수동적 AGENTS.md 색인이 53% 기준선 대비 100% 통과율을 달성했다는 점도 언급했다. 이는 Skills가 좁고 행동 중심적인 워크플로에 가장 적합하며, 전역 컨텍스트는 수동적이고 항상 접근 가능한 문서에 남아 있어야 한다는 점을 강화한다.
업계 표준에 가까운 90% 트리거 정확도를 달성하려면, 라우팅 시 모델이 볼 수 있는 유일한 요소인 SKILL.md의 description이 네 가지 검사를 통과해야 한다.
· 검증 가능한 구체성: 긍정 트리거 3개와 부정 트리거 3개를 쓸 수 있어야 한다.
· 명확성: 모호한 질의가 인접 Skill과 겹치지 않아야 한다.
· 실행 충실도: 실제로 수행할 수 있는 동작을 설명해야 하며, 희망 사항을 적어서는 안 된다.
· 재표현 안정성: 사용자가 같은 의도를 다르게 말해도 일관되게 같은 경로로 라우팅되어야 한다.
출력 품질과 도구 호출 궤적
Skill이 트리거된 뒤에는 두 가지를 분리해서 테스트해야 한다. 하나는 최종 출력, 즉 에이전트가 말하는 내용이다. 다른 하나는 도구 호출 궤적, 즉 에이전트가 실제로 수행하는 행동이다.
이를 위한 좋은 방법은 Evaluation-Driven Development, 즉 평가 주도 개발(EDD)을 사용하는 것이다. 일반적인 흐름을 뒤집어, SKILL.md를 작성하기 전에 세 개의 JSON 평가 케이스를 먼저 쓴다. 각 케이스에는 입력, 기대 도구, 기대 출력이 들어간다. 이렇게 하면 초기에 명확한 기능 명세를 강제할 수 있다. LLM-as-Judge를 사용해 대규모로 출력을 채점할 때는 두 가지를 반드시 지켜야 한다. 첫째, 순서 편향을 없애기 위해 참조 출력과 실제 출력의 위치를 바꿔 평가한다. 둘째, 사람의 평가와 보정해 90% 합의에 도달할 때까지 조정한다.
Latitude의 2026년 3월 분석[9]에 따르면, 최종 출력만 평가하는 방식은 도구 호출 궤적까지 고려하는 평가보다 20~40% 더 많은 케이스를 통과시킨다. 이 차이는 에이전트가 잘못된 도구 호출 순서를 거쳤지만 우연히 최종 정답에 도달한 경우를 의미한다. 읽기 전용 시나리오에서는 받아들일 수 있을지 모른다. 그러나 실행 허용형 Skill에서는 문제가 치명적이다. 잘못된 도구 호출 궤적은 되돌릴 수 없는 부작용을 만들 수 있기 때문이다.
Google ADK 평가 프레임워크[10]는 세 가지 궤적 채점 방식을 제공한다. EXACT는 정확한 순서를 요구하고, IN_ORDER는 순서가 있는 부분집합을 요구하며, ANY_ORDER는 순서를 따지지 않는 부분집합을 요구한다. 궤적 검증은 Skill의 권한 단계와 맞아야 한다. 읽기 전용 Skill은 ANY_ORDER를 사용할 수 있지만, 실행 허용형 Skill은 IN_ORDER나 EXACT가 필요하다.
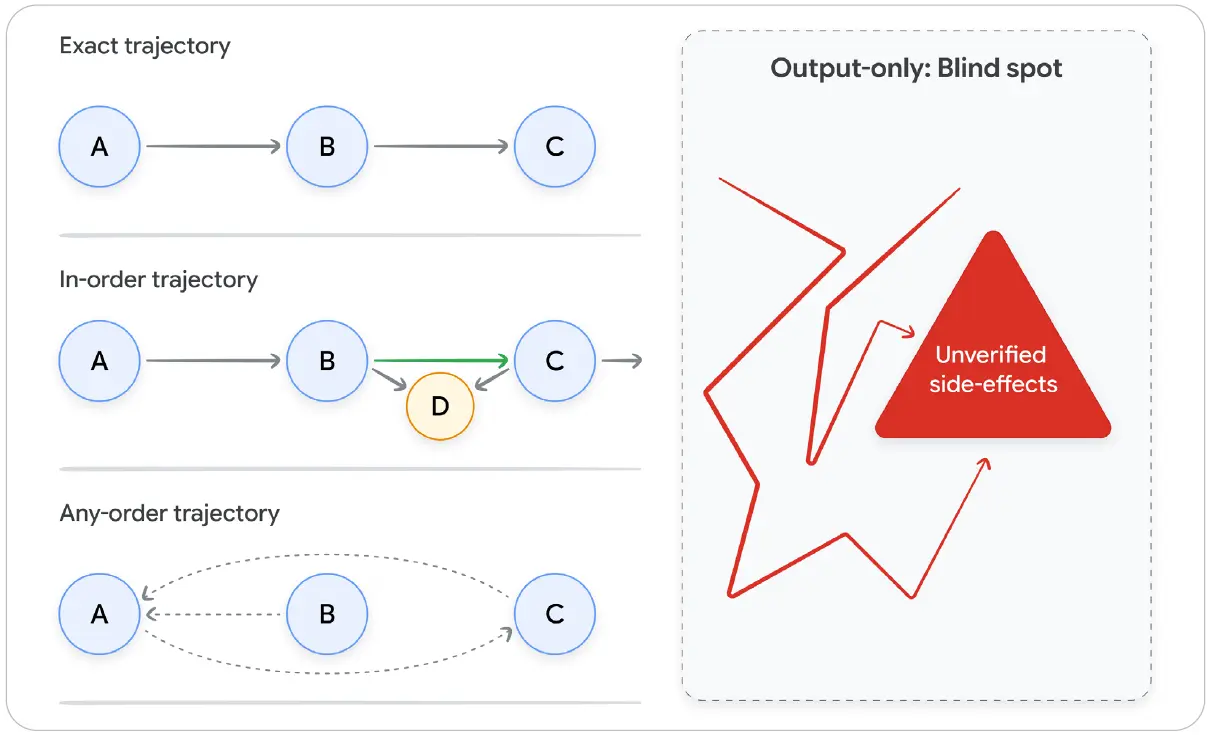
그림 3: 역전된 경로를 따라가라. 코드를 먼저 쓰는 대신, 이 워크플로는 기대 도구 호출 궤적과 평가 루브릭을 가장 첫 단계에서 정의하도록 강제한다.
그림 내 주요 문구 번역: Exact trajectory = 정확 궤적, In-order trajectory = 순서 포함 궤적, Any-order trajectory = 순서 무관 궤적, Output-only: Blind spot = 출력만 보는 평가의 사각지대, Unverified side-effects = 검증되지 않은 부작용.
시스템 vs. Skill: 평가의 착시
도구 호출 궤적 테스트는 Skill을 고립된 상태로 평가하는 것이 아니다. 실제로는 호스트 에이전트가 Skill과 상호작용하는 복합 시스템을 평가한다. 여러 Skill이 함께 관여한 궤적이 실패했을 때, 문제의 원인을 에이전트 라우팅, 지침 품질, 실행 충실도 중 어디에서 분리해 낼 수 없는 경우가 많다. 보정을 단순화하려면 “단일 Skill 하위 에이전트 패턴”, 즉 “Agent + 1 Skill”을 “Base Agent”와 비교하는 방식으로 Skill을 평가하라. 복잡한 다중 Skill 동시 로딩은 고급 프로덕션 스테이징 단계로 남겨 두는 것이 좋다.
Evaluation-Driven Development(EDD)[11]는 SKILL.md를 작성하기 전에 세 개의 JSON 평가 케이스, 즉 입력, 기대 도구, 기대 출력을 먼저 작성하도록 워크플로를 뒤집는다. 이 방식은 초기에 명확한 기능 명세를 강제한다. 최소 평가 케이스는 다음과 같다.
Snippet 3: Evaluation-Driven Development(EDD)에서 입력 매개변수, 기대 도구 궤적, 평가 루브릭을 미리 명시적으로 정의하는 최소 JSON 평가 케이스 예시.
{
“case_id”: “refund_dup_charge_001”,
“input”: “I was charged twice for order #4521 last Tuesday”,
“expected_skill”: “refund_processor”,
“expected_tool_calls”: [
{“tool”: “lookup_order”, “args”: {“order_id”: “4521”}},
{“tool”: “check_duplicate_charge”, “args”: {“order_id”: “4521”}}
],
“expected_output_format”: “confirmation_with_refund_id”,
“rubric”: [“acknowledges duplicate”, “cites order id”, “provides next step”]
}
이런 케이스 세 개를 먼저 작성하면, description의 모호성과 도구 호출 궤적 오류가 Skill 본문 안에서 복잡하게 증폭되기 전에 드러난다. LLM-as-Judge를 사용해 대규모로 출력을 채점할 때는 다시 한 번 두 가지가 필수다. 참조 출력과 실제 출력의 위치를 바꿔 순서 편향을 제거하고, 사람의 평가와 보정해 90% 합의에 도달해야 한다.
토큰 예산: 고립 평가는 함정이다
Skill을 절대로 순수하게 고립된 상태에서만 평가해서는 안 된다. 프로덕션 환경의 에이전트는 보통 5~15개의 Skill을 동시에 로드한다. Skill 본문이 5,000토큰을 넘으면 단독으로는 완벽하게 작동할 수 있다. 그러나 동시에 로드되면 컨텍스트 로트를 일으킨다.
복합 평가의 함정: Skill vs. Agent
도구 호출 궤적 테스트는 복합 시스템을 평가한다. Skill과 호스트 에이전트가 함께 평가 대상이 되는 것이다. 테스트가 실패했을 때 특정 모델에 맞추어 SKILL.md를 과도하게 엔지니어링하는 일은 피해야 한다. 그렇게 하면 이식성이 망가진다. 대신 “2계층 단언 프레임워크”를 사용해 실행 로직과 라우팅을 분리하라. 하위 도구 코드는 독립적으로 검증하고, SKILL.md 트리거는 여러 모델군에 걸쳐 감사하여 취약하고 특정 아키텍처에 묶인 description을 찾아내야 한다.
MCPVerse[12]는 도구가 과도하게 늘어나고 컨텍스트 주의가 경쟁하면서 Claude-4-Sonnet의 정확도가 18.2% 떨어졌다고 지적했다. 또한 Chroma Research 2025[13]는 동시 로딩된 소음이 방해할 때 모든 프런티어 모델의 성능이 입력 증가에 따라 저하된다는 점을 발견했다.
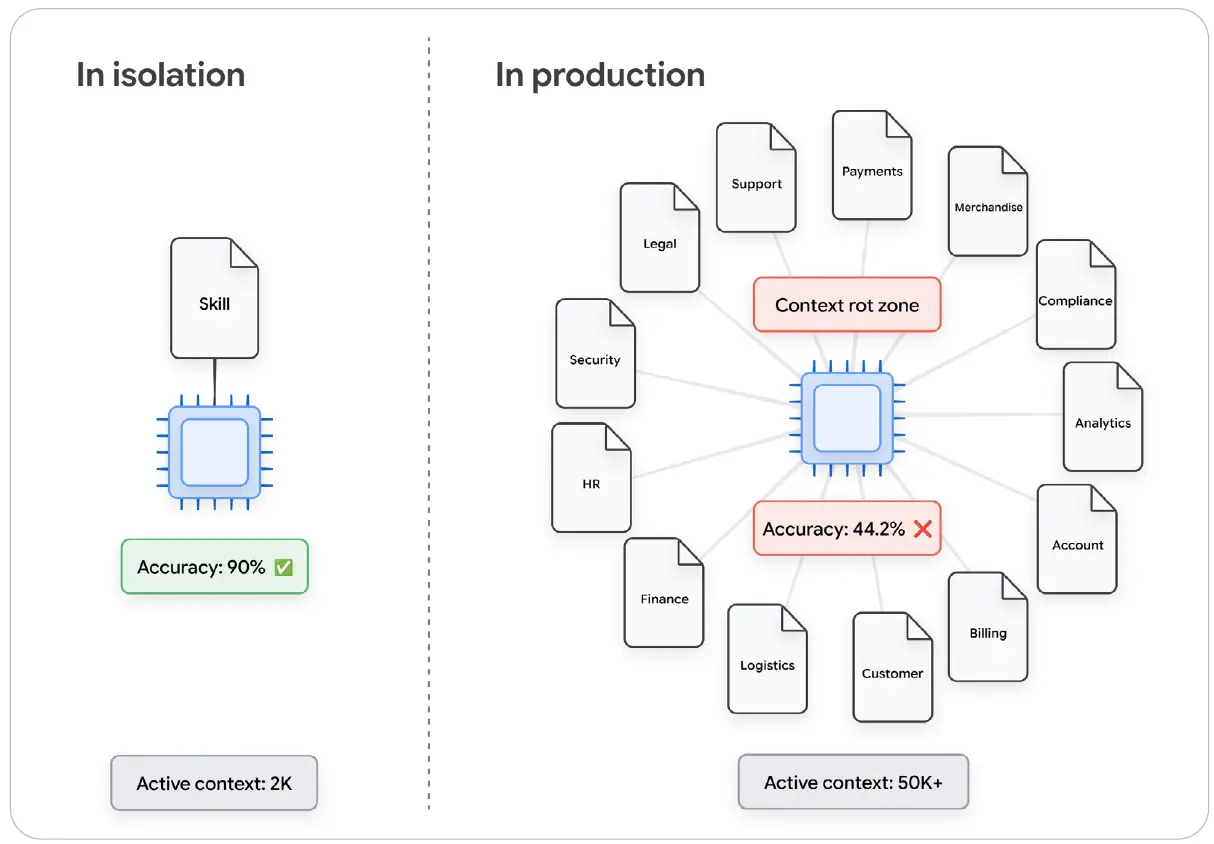
그림 4: 하나의 Skill만 실행할 때와 15개의 Skill을 동시에 로드할 때의 성능 차이를 보라. 이 곡선은 고립된 테스트를 통과했다는 사실이 왜 프로덕션 준비 완료의 거짓 양성일 수 있는지를 보여 준다.
그림 내 주요 문구 번역: In isolation = 고립 상태, In production = 프로덕션, Accuracy: 90% = 정확도 90%, Accuracy: 44.2% = 정확도 44.2%, Active context: 2K/50K+ = 활성 컨텍스트 2K/50K+, Context rot zone = 컨텍스트 로트 구간.
이 때문에 Skills는 엄격한 권한 단계를 거쳐 승격되어야 한다.
· Read-Only: LLM-as-Judge 평가, 90% 트리거 정확도.
· Draft-Only, Human Review: 20개 이상의 케이스로 구성된 골든 데이터셋, 사람의 승인.
· Action-Allowed: 완전한 적대적 레드팀 평가, 여러 번 실행해도 지속되는 성공, 단 한 번의 운 좋은 통과가 아님, 롤백 이벤트 없음, 지속적인 pass^k.
pass^k는 우연한 성공이 아니라 일관된 성공을 측정한다. 평가를 k번 실행하고 모든 실행에서 성공해야 통과로 본다. tau-bench(Yao et al., 2024)[14]에서 GPT-4o는 pass^1에서는 61%를 기록했지만 pass^8에서는 25% 아래로 떨어졌다. 이는 단일 실행 성공이 프로덕션 신뢰성을 예측하는 데 부적절하다는 점을 보여 준다.
이 기준을 보정할 때에는 두 가지 요소가 중요하다.
• 프로덕션 성능 저하: ReliabilityBench[15]는 프로덕션 성능이 오프라인 벤치마크의 pass@1 수치보다 보통 20~30% 낮아진다고 보여 준다.
• 시뮬레이션 편향: 시뮬레이션 기반 평가는 최대 9%까지 낙관적 편향을 보일 수 있다. 이는 “Lost in Simulation”[16]의 발견이다.
따라서 실행 허용 단계로 승격할 때 최종 검증 신호는 여전히 대표 출력에 대한 사람의 검토다.
“평가 커버리지”란 무엇을 뜻하는가
하나의 Skill이 완전한 평가 커버리지를 달성하려면, 주요 실패 모드에 직접 대응하는 네 가지 조건을 만족해야 한다.
· 트리거 실패: 긍정 테스트 케이스, 즉 켜져야 하는 경우와 부정 테스트 케이스, 즉 켜지면 안 되는 경우를 모두 검증한다.
· 실행 실패: 대표적인 기대 입력 범위 전반에서 올바른 출력이 나오는지 확인한다.
· 회귀: 새 Skill을 추가해도 기존 라이브러리의 성능이 전혀 떨어지지 않는지 확인한다.
· 토큰 예산 실패: Skill의 토큰 발자국을 제한해, 관련 없는 턴의 성능을 저하시키지 않도록 한다.
이 체크리스트가 승격을 결정한다. 어느 한 조건이라도 실패하면, 정상 경로 성능이 아무리 좋아도 해당 Skill은 Draft 단계에 머물러야 한다. 검증이 끝나면, Skill과 그에 딸린 평가 스위트는 프로덕션 배포 준비가 된 것이다. 그 구체적인 내용은 5장에서 다룬다.
5. 프로토타입에서 프로덕션으로
1장부터 4장까지는 Skill이 무엇인지, 어떻게 작성하는지, 그리고 어떻게 평가하는지를 다루었다. 이제 이 장에서는 작동하는 프로토타입을 실제 고객 앞에 놓는 순간 무엇이 달라지는지를 다룬다. 핵심만 말하면 이렇다. 이제 흥미로운 부분은 더 이상 모델이 아니다. 안정적으로 배포하고 운영할 수 있게 해 주는 엔지니어링 기본 단위가 바로 Skill이다.
Google의 Agent Platform에 포함된 Agents CLI[17]는 Google Cloud에서 AI 에이전트를 구축하고, 평가하고, 배포하기 위한 CLI이자 Skills 패키지다. 에이전트는 Google의 Agent Development Kit, 즉 ADK로 만들어지고, Agents CLI는 그 주변의 모든 일을 처리한다. 여기에는 스캐폴딩, 평가, 배포, 관측 가능성이 포함된다.
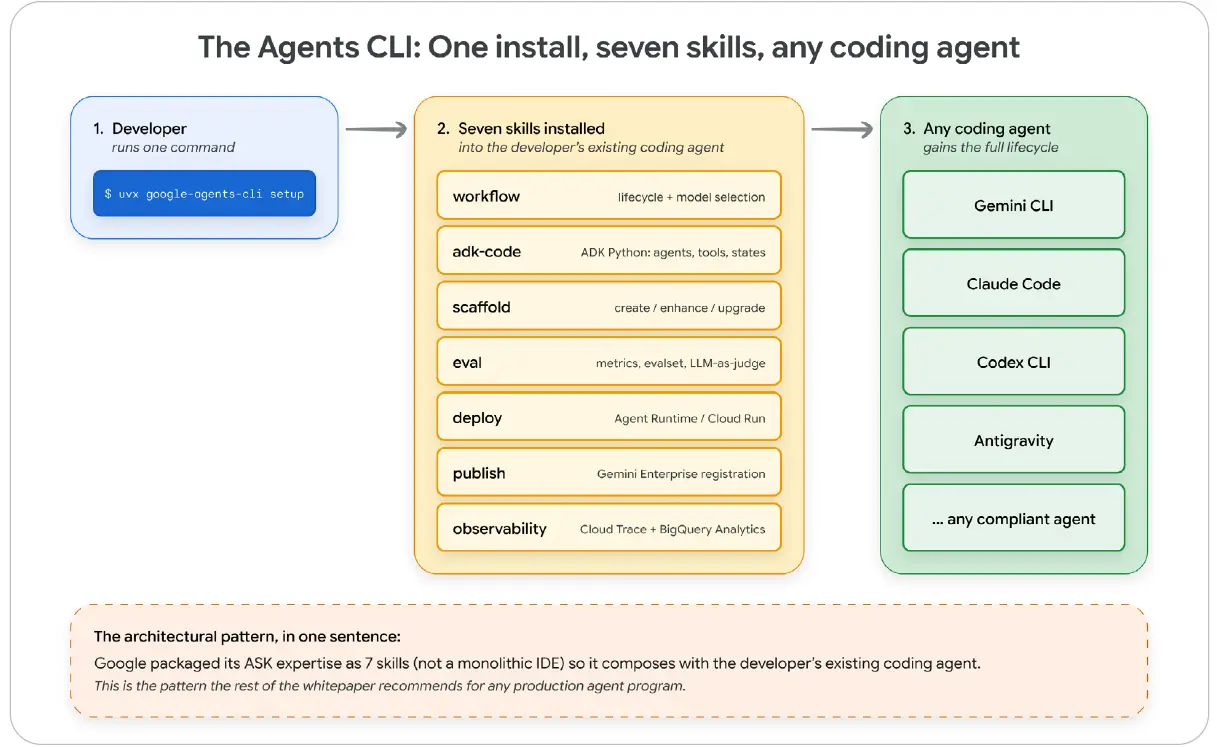
그림 5: Agents CLI 설치 흐름. 하나의 uvx 명령으로 개발자가 이미 사용하던 코딩 에이전트 안에 7개의 Skill이 설치된다. 이 7개 Skill은 workflow, adk-code, scaffold, eval, deploy, publish, observability로 구성되어 있으며, 전체 에이전트 라이프사이클을 포괄한다. 같은 Skills는 Claude Code, Codex CLI, Antigravity, 그리고 표준을 따르는 다른 코딩 에이전트에서도 작동한다.
그림 내 주요 문구 번역: The Agents CLI: One install, seven skills, any coding agent = Agents CLI: 한 번 설치, 일곱 개 Skill, 어떤 코딩 에이전트든 가능. The architectural pattern = 아키텍처 패턴.
이 작동 사례는 Google의 구성에만 국한되지 않고 일반화할 수 있는 세 가지 속성을 보여 준다.
· 전문성은 런타임이 아니라 Skills 안에 있다. 런타임은 범용재가 된다. 지속 가능한 핵심 자산은 7개의 Skills다.
· Skills 패키지는 이미 쓰고 있는 도구와 조합된다. Skills를 설치하면 기존 코딩 도구가 새로운 능력을 얻는다. 내부적으로도 별도의 포털을 새로 만들기보다, 기존 도구 안에 조합되는 역량을 목표로 삼아야 한다.
· 전체 라이프사이클이 Skills로 배포된다. 스캐폴딩, 빌드, 평가, 배포, 게시, 관측까지, 과거에는 각자 별도 도구가 필요했던 단계들이 이제 Skill 형식 안에 들어간다.
실제 Agent Runtime 안에는 무엇이 들어 있는가
프레임워크 아래를 보면, 에이전트 루프는 여러 벤더에 걸쳐 상당히 비슷한 형태로 수렴하고 있다. 런타임은 대화를 유지하고, 모델을 호출하고, 도구를 실행하고, 파일을 읽고, 응답을 반환한다. 이런 런타임 내부를 들여다볼 때 인상적인 점은, 코드 중 실제 “추론”에 해당하는 부분이 매우 작다는 것이다.
Claude Code v2.1.88을 역공학한 최근 분석(Liu, Zhao, Shang, Shen, 2026)[18]에 따르면, 코드베이스의 98.4%는 운영 인프라에 해당한다. 여기에는 권한 분류기, 컨텍스트 압축 파이프라인, 하위 에이전트 위임, 세션 저장소가 포함된다. 반면 에이전트 루프 자체는 1.6%에 불과하다. 모델은 원격 API 뒤에 있고, 시스템을 프로덕션급으로 만드는 것은 그 주변의 엔지니어링이다. 관련 companion site인 ccunpacked.dev는 같은 아키텍처를 시각적으로 매핑한다.
이것이 이후 논의의 바탕이 되는 아키텍처적 통찰이다. 기초 모델들의 기본 추론 능력이 서로 수렴할수록, 자율 에이전트의 신뢰성을 가르는 차별화 요소는 모델 주변의 결정론적 엔지니어링이 된다. 그리고 그 엔지니어링 안에서 조합되고 재사용되는 단위가 바로 Skill이다.
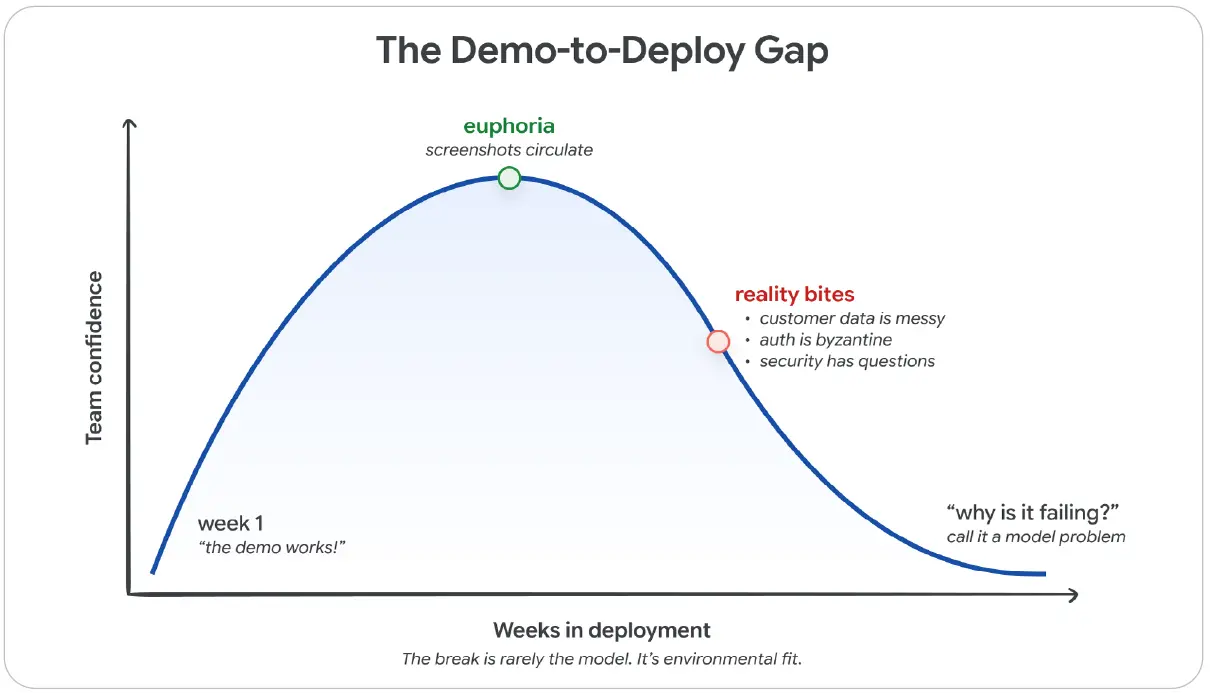
그림 6: 데모-배포 간극. 팀의 자신감은 초기에 최고점에 도달한 뒤, 실제 고객 환경을 만나면 급락한다. 본능적으로 이를 모델 문제라고 부르지만, 실제로는 거의 언제나 환경 적합성 문제다.
그림 내 주요 문구 번역: The Demo-to-Deploy Gap = 데모-배포 간극, euphoria = 도취감, reality bites = 현실의 충격, “why is it failing?” call it a model problem = “왜 실패하지?” 모델 문제라고 부르기.
왜 Skills가 개선의 단위인가
에이전트 개선에 대한 순진한 생각은 “더 좋은 모델이 더 좋은 에이전트를 만든다”는 것이다. 그러나 프로덕션에서는 모델이 인프라에 가깝고, 개선 사항을 실제로 배포 가능하게 만드는 기본 단위는 Skills다. 각각의 새 Skill은 작고, 소유자가 명확하며, 테스트 가능한 역량 단위다. 새로운 경계 사례가 나타나면 하나의 SKILL.md를 수정하면 된다. 단일 거대 프롬프트 엔지니어링의 어려움 없이, 에이전트의 실질적 역량이 확장된다.
Skills가 이 역할을 할 수 있는 이유는 세 가지다.
· 조건부로 로드된다. Skill은 description이 작업과 맞아떨어질 때만 로드된다.
· 조합 가능하다. 하나의 Skill이 다른 Skill의 도구를 호출하거나 후속 단계로 연결될 수 있다. 서로가 서로를 직접 알 필요도 없다. 7장에서는 이 조합 이야기를 더 깊이 다룬다.
· 소유권이 명확하다. 각 Skill은 명확한 작성자가 있는 버전 관리 폴더 안에 존재한다. 따라서 개선 작업이 중앙 플랫폼팀의 병목에 걸리지 않고 여러 팀으로 분산된다.
다른 개선 방식과 비교하면 차이가 더 분명해진다.
| 개선 방식 | 소요 시간 | 실패 모드 | 수행 주체 | 컨텍스트 비용 |
| 모델 교체 | 며칠~몇 주 | 관련 없는 작업에서 회귀 발생 | ML/플랫폼팀 | 없음, 가중치 기반 |
| 시스템 프롬프트 수정 | 몇 분~몇 시간 | 컨텍스트 로트, 지시 충돌 | 프롬프트 파일 소유자 | 정적 비용, 매 턴마다 지불 |
| 파인튜닝 | 몇 주~몇 달 | 재앙적 망각, 과적합 | ML팀만 가능 | 없음, 가중치 기반 |
| 새 Skill 추가 | 몇 시간~며칠 | 매칭되는 턴에만 제한적으로 발생 | 어떤 도메인팀이든 가능 | 동적 비용, 트리거될 때 필요 시 로드 |
데모를 깨뜨리는 실패 모드: 컨텍스트 오버플로
프로덕션에서 에이전트가 가장 흔히 겪는 실패 모드는 환각이 아니다. 더 흔한 문제는 컨텍스트 오버플로다. 이는 모델이 효과적으로 사용할 수 있는 양보다 더 많은 컨텍스트를 받아들이고, 운영자가 알아차리기 전에 조용히 성능이 떨어지는 현상이다. 원문은 이 주장을 두 갈래 연구 흐름으로 뒷받침한다.
Lost in the Middle(Liu et al., TACL 2024)[19]. 다중 문서 질의응답과 검색 작업에서, 관련 정보가 입력의 시작이나 끝에 있을 때 성능이 가장 높고, 중간에 있을 때 성능이 떨어진다. 이 U자형 곡선은 긴 컨텍스트에 맞춰 훈련된 모델에서도 유지된다.
Context Rot(Chroma Research, 2025)[20]. Claude 4 Opus와 Sonnet, Gemini 2.5, Qwen3 등 18개 프런티어 모델 전반에서 입력이 길어질수록 성능이 저하된다. 작업 난이도를 고정해도 마찬가지다. 모든 모델이 나빠지며, 관련 정보가 방해 요소와 구별되기 어려울수록 더 빠르게 나빠진다. 실제 에이전트 컨텍스트에서 흔히 나타나는 도구 출력, 반쯤 관련 있는 검색 결과, 중간 추론 같은 잡음은 특히 나쁜 조건에 속한다.
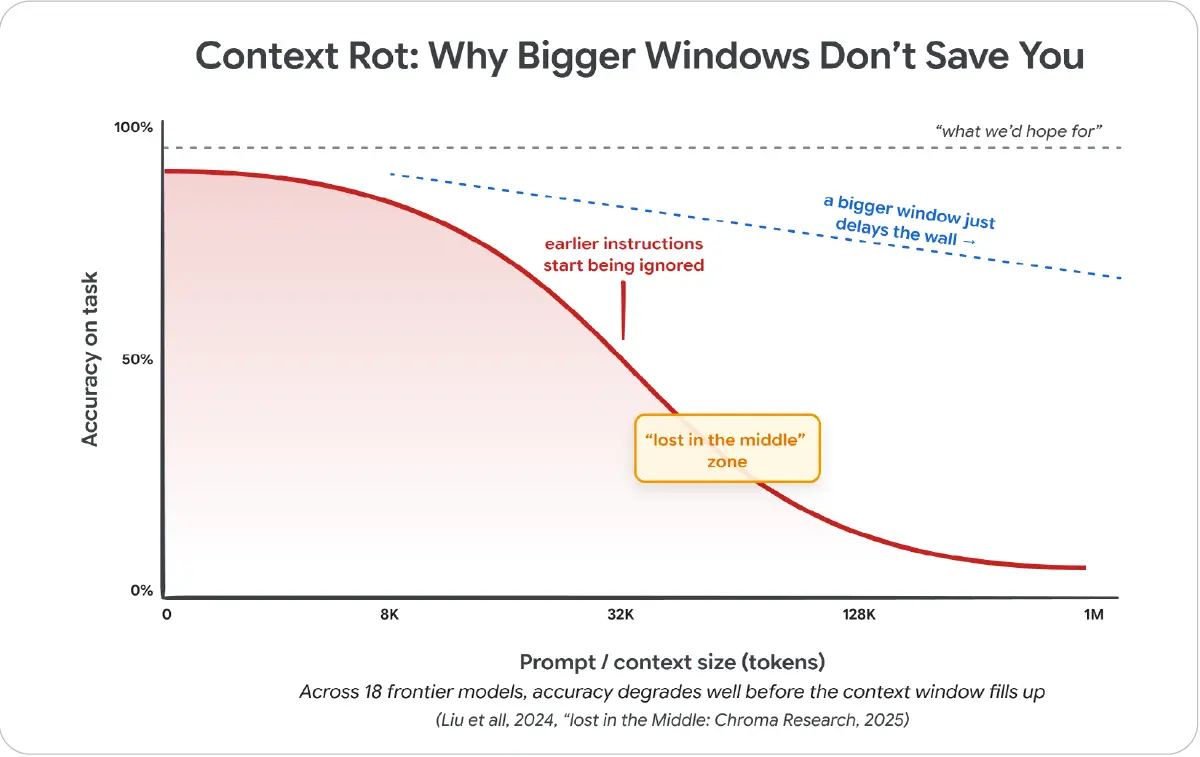
그림 7: 컨텍스트 로트가 실제로 어떻게 나타나는지 보여 준다. 프롬프트 크기가 커질수록, 컨텍스트 윈도우가 가득 차기 훨씬 전부터 고정된 작업의 정확도가 떨어진다. 점선은 순진한 기대를, 곡선은 18개 프런티어 모델이 실제로 보인 모습을 나타낸다.
그림 내 주요 문구 번역: Context Rot: Why Bigger Windows Don’t Save You = 컨텍스트 로트: 더 큰 윈도우가 왜 구해 주지 못하는가, earlier instructions start being ignored = 앞쪽 지시가 무시되기 시작함, “lost in the middle” zone = 가운데서 길을 잃는 구간.
이것이 토큰 예산에 의미하는 것
2장에서 다룬 점진적 공개가 이 문제에 대한 아키텍처적 답이다. 모든 Skill의 메타데이터는 시작 시 로드된다. 그러나 Skill 본문은 description이 작업과 일치할 때만 로드된다. 그리고 보조 파일은 Skill 본문이 그것을 참조할 때에만 로드된다.
수치로 보면 더 분명하다. 서로 다른 워크플로가 50개 있는 에이전트를 생각해 보자. 이를 하나의 시스템 프롬프트로 구성하면 매 턴마다 15,000토큰을 로드한다. 반면 Skills 라이브러리로 구성하면, 약 4,000토큰의 description과 활성화된 Skill 하나의 약 2,000토큰 본문만 로드한다. 총 약 6,000토큰이다. 나머지 49개 Skill 본문은 디스크에 남아 있다. Anthropic은 어떤 워크플로를 Skills로 전환했을 때 활성 컨텍스트가 약 150,000토큰에서 2,000토큰으로 줄어들어 98% 이상 감소한 사례를 공개한 바 있다.
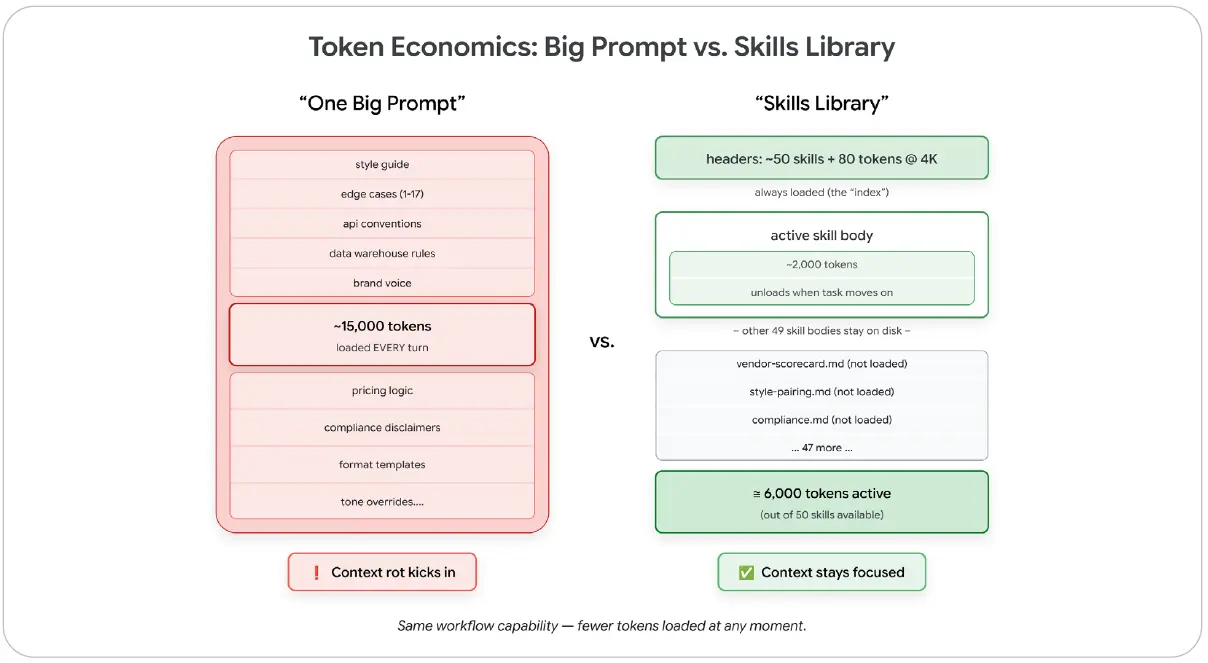
그림 8: 토큰 경제: 하나의 거대 프롬프트와 50개 Skill 라이브러리 비교. 라이브러리는 50개의 역량 단위를 사용할 수 있게 하지만, 어느 순간에도 실제 컨텍스트 안에는 활성화된 본문 하나만 들어간다.
그림 내 주요 문구 번역: One Big Prompt = 하나의 거대 프롬프트, Skills Library = Skill 라이브러리, Context rot kicks in = 컨텍스트 로트 시작, Context stays focused = 컨텍스트가 초점을 유지함.
여기서 세 가지 실무적 함의가 나온다.
· 용량은 잘못된 지표다. 100만 토큰 윈도우가 있어도 5만 토큰 수준에서 이미 의미 있는 성능 저하가 나타날 수 있다.
· 활성 컨텍스트는 그릇이 아니라 예산이다. 모델 앞에 놓이는 모든 토큰은 다른 모든 토큰에서 주의력을 빼앗는다. 시스템 프롬프트는 인프라팀이 메모리를 다루듯, 의도적으로 할당해야 하는 유한 자원으로 보아야 한다.
· Skills는 이 제약을 해결한다. Skills는 활성 컨텍스트를 작게 유지하면서도 사용 가능한 역량을 사실상 제한 없이 확장할 수 있게 해 준다.
팀이 작동하는 Skill 라이브러리를 갖추게 되면, 질문의 초점은 단일 Skill을 유지하는 일에서 벗어난다. 이제 관심사는 진화, 조합, 그리고 더 큰 생태계로 이동한다.
6. 메타 스킬과 자기 개선형 Skill에 대하여
지금까지 이 문서에서 다룬 모든 Skill은 사람이 작성한 것이었다. 도메인 전문가가 자리에 앉아 SKILL.md를 초안 작성하고, 테스트하고, 배포한다. 시작점으로는 이것이 맞다. 하지만 일단 작동하는 Skill 라이브러리가 생기면, 자연스럽게 다음 질문이 떠오른다. 에이전트도 Skill을 작성하고, 평가하고, 개선하는 일을 도울 수 있을까?
바로 여기서부터가 메타 스킬의 영역이다. 메타 스킬이란 다른 Skill을 작성하거나, 평가하거나, 개선하는 일을 맡는 Skill이다. 실제로 이런 “메타 스킬”은 네 가지 범주로 나눌 수 있다.
• 작성. 워크플로 설명을 입력받아 SKILL.md 초안을 만들어 내는 Skill이다. Google의 ADK[21]에는 SkillToolset을 통해 이런 작업을 수행하는 “Skill 팩토리” 패턴이 있다. Anthropic 역시 skill-creator Skill[22]을 제공하는데, 이는 Skill 생성, 평가, 튜닝 과정을 단계별로 안내한다.
• 실행 추적 기반 작성 보조. 이 방식은 사람에게 워크플로를 설명하라고 요구하지 않는다. 대신 에이전트가 같은 작업을 몇 차례 성공적으로 수행하는 모습을 관찰한 뒤, 그 실행 추적을 Skill로 전환한다. skill-creator 워크플로는 이런 실행 추적 기반 포착을 직접 지원한다. 이때 사람의 역할은 Skill을 처음부터 작성하는 것이 아니라, 자동으로 포착된 버전이 올바른 단계를 제대로 담고 있는지 확인하는 쪽으로 이동한다.
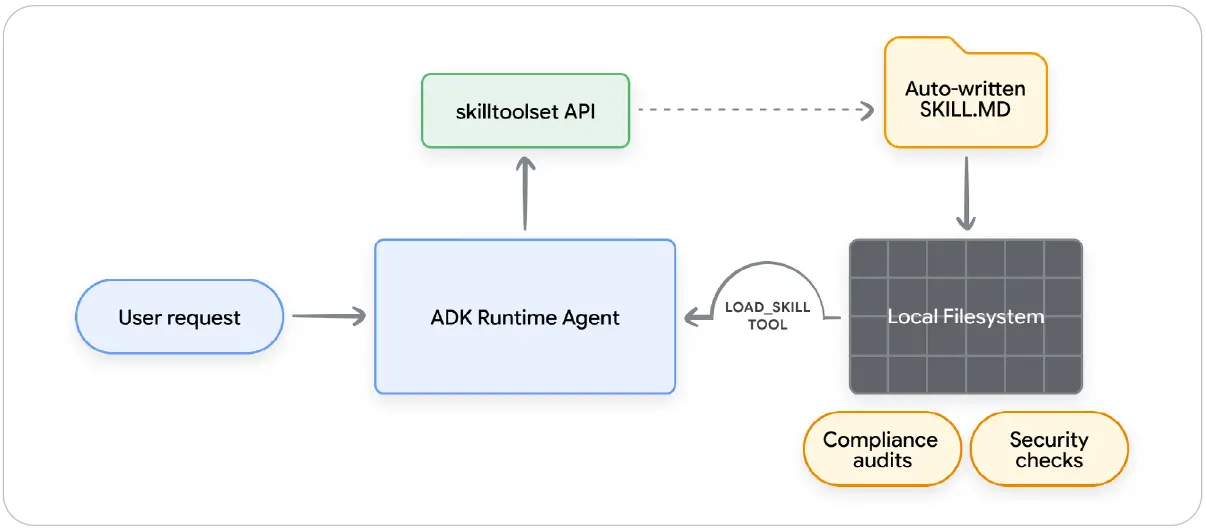
그림 9: 단계별 루프는 실제 운영에서 성공한 실행 이력이 어떻게 신뢰 가능한 절차기억으로 바뀌는지를 보여 준다. 이 과정은 사람이 처음부터 수동으로 초안을 작성하지 않아도 가능하다.
그림 내 주요 문구 번역: User request = 사용자 요청, ADK Runtime Agent = ADK 런타임 에이전트, SkillToolset API = SkillToolset API, Auto-written SKILL.MD = 자동 작성된 SKILL.md, Local Filesystem = 로컬 파일 시스템, Compliance audits = 컴플라이언스 감사, Security checks = 보안 점검, LOAD_SKILL TOOL = LOAD_SKILL 도구.
• 개선. 기존 Skill과 실패한 평가 케이스 묶음을 입력받아 수정안을 제안하는 Skill이다. Saboo의 SkillOptimizer[24]와 Anthropic의 description 최적화 루프가 이런 예에 해당한다. 또 다른 예로는 Karpathy의 autoresearch 패턴[25]이 있다. 이 패턴에서는 에이전트가 대상 파일에 대한 변경을 제안하고, 제한된 실험을 실행한 뒤, 지표가 개선될 때에만 해당 변경을 유지한다.
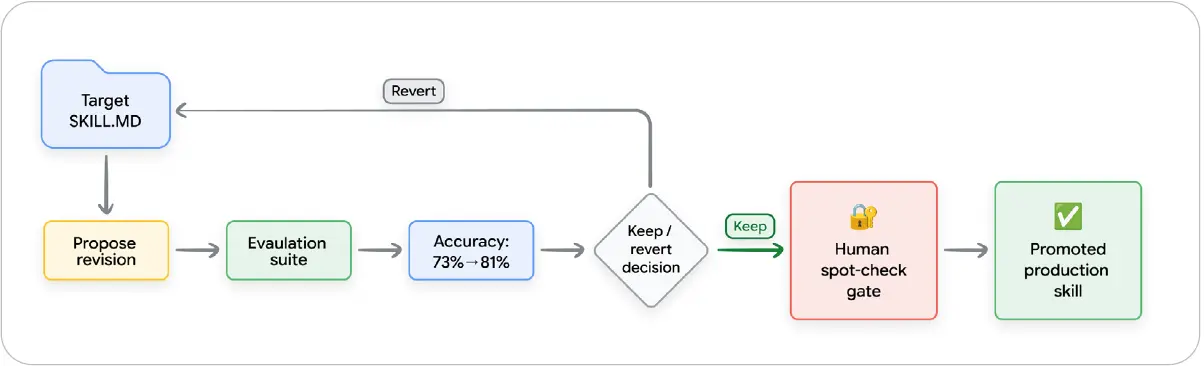
그림 10: 평가 게이트를 주목하라. 에이전트는 description이나 지침 수정을 제안할 수 있지만, 단위 테스트를 통과하지 못하면 그 변경을 라이브러리에 커밋할 수 없다.
그림 내 주요 문구 번역: Target SKILL.MD = 대상 SKILL.md, Propose revision = 수정 제안, Evaluation suite = 평가 스위트, Accuracy: 73%→81% = 정확도 73%에서 81%로, Keep/revert decision = 유지/되돌리기 결정, Human spot-check gate = 사람의 표본 검토 게이트, Promoted production skill = 프로덕션 Skill로 승격.
• 라이브러리 진화. 시간이 지남에 따라 Skill 라이브러리를 성장시키는 Skill이다. Voyager가 자체 Minecraft Skill 라이브러리를 키워 나간 방식[26]이 대표적이다. 에이전트가 기존에 Skill이 없던 작업을 완료하고, 방금 해결한 문제가 반복될 가능성이 있다는 점을 알아차린 뒤, 이를 다룰 새 Skill 추가를 제안한다. Schmid의 self-learning-skill[27]은 이 패턴의 커뮤니티 참조 구현이다.
어디서 이 방식이 무너지는가
메타 스킬은 평가 스위트가 좋을 때에만 작동한다. 자기 자신의 Skill을 수정할 수 있도록 허용된 에이전트는 우리가 지정한 지표를 기꺼이 최적화한다. 문제는 그 지표가 쉽게 속일 수 있는 지표일 수도 있다는 점이다. 4장에서 다룬 평가 작업은 바로 이 과정을 정직하게 유지하는 장치다. 탄탄한 트리거 정확도 테스트, 회귀 테스트, 사람의 표본 검토가 없다면, 자율 개선 루프는 조용히 Skill 라이브러리를 더 나쁘게 만들 수 있다. 더 위험한 점은, 시스템이 그러는 동안에도 “성능이 좋아지고 있다”고 보고할 수 있다는 것이다.
실무에서 비교적 잘 버틴 습관은 다음과 같다.
· 에이전트가 작성한 것은 무조건 Draft 단계로 들어간다. 메타 스킬이 아무리 자신 있어 해도, 에이전트가 작성한 Skill은 곧바로 프로덕션 라이브러리에 들어가지 않는다. 사람이 쓴 Skill과 마찬가지로 4장의 Read / Draft / Act 사다리를 통과해야 한다.
· 처음 몇 번의 수정에는 사람을 루프 안에 둔다. 지표가 분명히 개선되어 보여도 diff를 훑어봐야 한다. 에이전트가 흔히 저지르는 실수, 예를 들어 description을 몇 개 테스트 케이스에 과적합시키거나 자신이 알지 못하는 후속 Skill을 깨뜨리는 문제는 사람이 30초 만에 발견할 수 있는 종류의 오류다.
· 메타 스킬부터 시작하지 않는다. 먼저 사람이 직접 작성하고 평가하는 수동 루프를 안정화해야 한다. 빈 폴더를 에이전트에게 던져 주고 Skill 50개를 생성하라고 하는 것은 나쁜 라이브러리를 가장 빠르게 만드는 방법이다.
이 흐름은 어디로 가고 있는가
현재 패턴은 대체로 다음과 같은 방향으로 정착하고 있다. 모든 Skill의 첫 버전은 사람이 작성하고, 메타 스킬은 반복적인 유지보수 작업을 맡는다. 여기에는 description 튜닝, 테스트 케이스 추가, 회귀 탐지 같은 작업이 포함된다. 그리고 일부 팀만이 완전한 자기 확장, 즉 에이전트가 새 Skill을 제안하고 라이브러리를 직접 확장하는 실험을 하고 있다. 가장 흥미로운 최전선은 세 번째 범주, 즉 에이전트가 프로덕션 트래픽에서 관찰한 내용을 바탕으로 새 Skill을 제안하는 영역이다. 가능성은 크다. 그러나 평가 게이트가 촘촘하지 않다면 가장 빠르게 망가지는 지점도 바로 여기다.
이 문제의 실무적 버전은 Appendix A에서 다시 다룬다. 그곳의 치트시트는 에이전트가 자기 Skill을 작성하게 하고 싶어질 때 무엇을 해야 하고, 무엇을 하지 말아야 하는지를 정리한다.
7. Skills 조합과 패키징
실제 워크플로는 하나의 Skill 안에 깔끔하게 들어가지 않는다. 따라서 조합 문제의 핵심은 Skills가 서로를 어떻게 참조하고, 상태를 어떻게 전달하며, 순환 의존성을 어떻게 피할 것인가에 있다.
단일 거대 시스템 안에서 고립된 Skills 사이에 가공되지 않은 LLM 출력을 그대로 넘기는 방식은 효과적이지 않다. 상태는 불투명해지고, 실행은 비결정적으로 변하며, 디버깅은 어려워진다. 에이전트 아키텍처는 순진한 프롬프트 체이닝에서 벗어나, 예측 가능한 오케스트레이션으로 진화해 왔다.
실행 라우팅: DAG 오케스트레이션
초기의 아키텍처는 취약했다. 특히 앞단의 단계가 환각을 일으키면, 그 오류가 뒤 단계로 누적·증폭되기 쉬웠다. 이에 대한 업계의 해법은 Directed Acyclic Graph, 즉 DAG 오케스트레이션이다.
· 분리된 상태. DAG 아키텍처에서 상태 라우팅은 LLM 프롬프트 안에 실행 이력을 계속 누적하는 방식에 의존하지 않는다.
· 파일 메시지 버스. DAG 컨트롤러는 하위 에이전트 노드들 사이에 구조화된 스키마 참조를 전달함으로써 핸드오프를 조율한다.
· 주의력 보호. 페이로드를 모델의 텍스트 입력에서 추상화하면 컨텍스트 윈도우의 비대화를 막을 수 있고, 모델의 처리 역량도 보존할 수 있다.
환경 패키징: Capability Profiles
모든 Skill을 한꺼번에 활성화하면 자연어 라우팅 품질이 떨어지고, 컨텍스트 윈도우도 압도된다. 따라서 아키텍트는 Capability Profiles, 즉 역량 프로필을 관리하는 도구를 활용해야 한다. 이 프로필은 특정 실행 상태에 맞춰 조정된 전문 페르소나처럼 작동한다. 하나의 프로필은 다음 요소를 정의하는 모듈식 도구 번들이다.
· 활성 Skills와 도구 접근 권한.
· 시스템 지침과 운영 가드레일.
· 자동화 워크플로와 하위 에이전트 토폴로지.
· 모델 선택, temperature 같은 LLM 파라미터.
실행 중에는 오케스트레이션 계층이 이전 시스템 지침을 언로드하고, 낡은 변수를 비운 뒤, 새로운 Capability Profile을 메모리로 교체한다. 이런 엄격한 해체 후 재구축 과정은 맥락 손실을 방지한다.
그래프 채우기: 정식 Skill 분류 체계
DAG를 구성하려면 개별 엔지니어링 역량을 실행 그래프 안의 특정 노드 기능으로 매핑해야 한다. 7장은 이를 위한 정식 Skill 분류 체계를 다음과 같이 제시한다.
· Generator: 사용자 의도를 구조화된 산출물로 변환한다.
· Reviewer & Gate: 검증이 실패하면 실행을 막는 결정론적 게이트 역할을 한다.
· Pipeline: 더 큰 DAG 환경 안에서 선형 경로를 조율한다.
· Inversion & Recovery: 실행 전에 에이전트가 가정을 명확히 하도록 강제한다.
· Domain Context Wrappers: 도메인 관례를 가르치는 참조 노드로 작동한다.
컨텍스트 부채와 지능의 앞단 이동
Skills는 모델의 주의력을 소비한다. 그리고 모델의 주의력은 희소한 자원이다. 작성자가 런타임에서 결정론적 동작을 강제하려고 Skill 설명을 계속 부풀리면, 예컨대 “ALWAYS DO X” 같은 지시를 덧붙이면, 컨텍스트 부채가 쌓인다. 모델은 이런 대문자 명령문을 점점 무시하는 법을 배운다. 마치 인간 개발자가 읽기 어려운 경고문이 벽처럼 붙어 있으면 결국 무시하게 되는 것과 같다.
엔지니어링의 모범 사례는 Shift Intelligence Left, 즉 지능을 앞단으로 이동시키는 것이다. 복잡한 규칙을 런타임에서 LLM이 잘 해석해 주기를 바라지 말고, 주관적 판단을 Skill과 테스트 가능한 구조 안으로 정제해야 한다. 더 나아가 로직을 LLM 프롬프트 밖으로 밀어내어 표준화되고 테스트 가능한 스크립트로 옮기면, 애플리케이션의 혼란스러운 실패 표면을 줄일 수 있다.
아키텍처별 트레이드오프
| 아키텍처 | 메커니즘 | 주요 장점 | 적합한 경우 |
| 선형 파이프라인 | 고정된 노드 사이에서 텍스트를 순차적으로 전달한다. | 엔지니어링 부담이 낮고 빠른 프로토타이핑이 가능하다. | 단일 도메인, 낮은 복잡도의 생성 작업 |
| DAG 오케스트레이션 | 그래프 기반 병렬 실행을 사용하며, 스키마 참조를 통해 파일 버스 방식으로 상태를 전달한다. | 순환을 방지하고 컨텍스트를 엄격하게 격리한다. | 높은 신뢰성이 필요한 멀티 에이전트 워크플로 |
| Capability Profiles | 버전 관리 가능한 파라미터와 도구 번들을 교체 가능하게 구성한다. | 생애주기 메모리 정리를 동반한 빠른 페르소나 전환이 가능하다. | 역할 기반 배포와 도메인 특화 에이전트 |
바로 적용할 수 있는 모범 사례
· 규칙을 쓰지 말고 소프트웨어를 작성하라. 부정형 LLM 지시를 덧붙이는 대신, 잘못된 행동 자체가 불가능해지도록 결정론적 소프트웨어 제약으로 바꾸어라.
· 점진적 공개를 구현하라. 복잡한 지침은 Skill이 명시적으로 호출될 때에만 동적으로 로드하라.
· 상태를 분리하라. LLM 컨텍스트 윈도우를 데이터베이스처럼 사용하지 말라. 하위 에이전트에게는 파일 시스템이나 메시지 버스를 통해 URI 또는 포인터만 전달하라.
8. 이미 존재하는 수많은 Skill 중 무엇을 선택할 것인가
2026년 초가 되자 공개 Skill 마켓플레이스의 등록 항목은 40,000개를 넘어섰다. 선도 플랫폼 중 하나는 1월 첫 몇 주 동안에만 수만 개의 새 Skill이 게시되었다고 보고했다. Google Cloud Next 2026에서 Google은 공식 Agent Skills 저장소인 github.com/google/skills를 공개했으며, 이 Skill들은 npx skills install github.com/google/skills 명령으로 설치할 수 있다. Antigravity CLI뿐 아니라 Skills 표준을 지원하는 다른 코딩 에이전트에서도 사용할 수 있다. Anthropic의 Skills 저장소, Google ADK Skill 라이브러리, Google 공식 Skills 저장소, 그리고 awesome-llm-apps 같은 커뮤니티 마켓플레이스에는 이제 어떤 실무자도 하나하나 검토할 수 없을 만큼 많은 Skill이 올라와 있다. 선택 문제는 현실이 되었고, 계속 커지고 있다.
이때 도움이 되는 판단 규칙은 세 가지다.
• 특정 벤더 도구에는 1st-party Skill을 우선하라. Google의 BigQuery Skill, 공식 Stripe Skill처럼, 기반 시스템을 만든 사람들이 직접 작성한 Skill을 우선 선택하라. 이런 Skill은 커뮤니티 대안보다 정확할 가능성이 높고, 유지보수도 더 잘될 가능성이 높다.
• 의존하는 모든 것은 버전을 고정하라. 커뮤니티 Skill은 계속 변한다. 어제는 잘 작동하던 고정되지 않은 의존성이 내일은 실패할 수 있다.
• 도입하기 전에 감사하라. Skill은 당신의 컨텍스트 안에서 실행되는 코드다. 다른 의존성과 똑같이 취급하라. 동일한 수준의 공급망 보안 관리가 필요하다.
모든 출처가 같은 것은 아니다. 2026년 초 기준으로 Skill 출처는 세 범주로 나눌 수 있으며, 각 범주에 맞는 운영 태세도 달라야 한다.
| 출처 | 기본 신뢰 태세 | 예시 | 유지보수 주체 |
| 1st-party 벤더 Skill | 기본적으로 신뢰하되, 버전은 고정한다. | google/agents-cli[28], google/skills[29], google-gemini/gemini-skills[30], anthropics/skills[31], stripe/ai[32], microsoft/skills[33] |
기반 제품을 만든 팀 |
| 조직 선별 Skill | 조직 내부에서는 신뢰하되, 도입 시 검토한다. | your-org/retail-skills, your-org/finance-skills처럼 비공개로 내부 유지보수되는 저장소 |
조직 내부 도메인 팀, PR 리뷰 포함 |
| 커뮤니티 Skill | 도입 전에 감사하고, 적극적으로 버전을 고정한다. | VoltAgent/awesome-agent-skills[34], SkillsMP marketplace[35], addyosmani/agent-skills[36], 개별 GitHub 저장소 |
자원 기여자. 유지보수 지속성은 제각각 |
9. 결론
우리는 이 백서를 놀라울 만큼 단순한 개념에서 시작했다. 하나의 마크다운 파일과 몇 개의 선택적 스크립트를 담은 폴더. 그러나 이 가벼운 구조, 즉 Agent Skill은 우리가 AI Agent를 구축하는 방식을 근본적으로 바꾸고 있다. Agent Skill은 마침내 기초 모델에 진정한, 검증 가능한 절차기억을 제공한다. 다시 말해 모델이 어떤 일을 단계별로 어떻게 수행해야 하는지를 기억할 수 있게 한다. 또한 Skills는 점진적 공개의 힘을 통해 컨텍스트 로트 문제를 해결한다. 이제 하나의 범용 에이전트는 토큰 예산을 막히게 하지 않으면서도 여러 전문 워크플로에 자연스럽게 접근할 수 있다.
이 글에서 우리가 반복해서 돌아온 패턴은 이것이다. 형식은 의도적으로 작게 설계되어 있으며, 그래서 흥미로운 작업은 그 안이 아니라 그 주변에서 일어난다. 현실적인 동시 로딩 조건에서 Skills를 평가하는 일이 중요하다. 컨텍스트 윈도우를 메시지 버스처럼 사용하지 않으면서 Skills를 워크플로로 조합하는 일이 중요하다. 사람이 처음부터 작성하는 대신, 에이전트가 성공적인 실행 추적을 바탕으로 Skill 초안을 만들고 사람이 검토하는 일이 중요하다. 20년에 걸쳐 축적된 조직 지식을 버전 관리 가능하고, 테스트 가능하며, 거버넌스 가능한 라이브러리로 인코딩하는 일이 중요하다. 이 모든 일은 12개월 전만 해도 지금만큼 다루기 쉬운 문제가 아니었다. 이제는 가능해졌다. 그 기본 구성 단위가 생겼기 때문이다.
이 백서 전체에서 우리는 무엇이 이미 정착되었고, 무엇이 아직 떠오르는 중이며, 무엇이 앞으로 바뀔 가능성이 큰지를 구체적으로 구분하려고 했다. 형식은 정착되었다. agentskills.io는 이제 공개 표준이며, 주요 코딩 에이전트, AI 챗봇, 에이전트 프레임워크 전반에서 채택되고 있다. 반면 그 주변의 아키텍처는 아직 형성 중이다. 동시 로딩 조건에서의 평가, Skill 라이브러리 수준의 최적화, 에이전트 주도 Skill 생성, 그리고 이 모든 것을 대규모로 안전하게 만드는 거버넌스 패턴은 여전히 진화하고 있다.
오늘 시작한다면, 우리의 제안은 이 백서 내내 반복해 온 것과 같다. 작게 시작하라. 이미 가지고 있는 지식에서 출발하라. Skills를 코드처럼 다루라. 배포한 것을 측정하라. 그리고 Skills로 충분한 곳에 멀티 에이전트 아키텍처를 성급히 끌어오지 말라. 지금 이 원리를 이해하는 팀은 업계 합의가 뒤늦게 따라오기를 기다리는 팀보다 더 깔끔한 시스템을 만들 것이다.
형식은 정착되었다. 일은 이제 막 시작되었다.
Appendix A – 실무 치트시트
이 섹션은 인쇄해서 독립적으로 사용할 수 있도록 설계되었다. 백서의 나머지 내용을 팀이 실제로 마주하게 될 결정들로 압축한 것이다.
최소한의 SKILL.md
그대로 복사해 붙여 넣어라. 자리표시자만 바꾸면 끝이다.
name: skill-name
description: |
[이 Skill이 하는 일을 동사로 시작하는 한 문장으로 적는다.]
사용자가 [트리거 문구 1], [트리거 문구 2], 또는 [트리거 문구 3]을
요청할 때 이 Skill을 사용한다.
[비활성화 조건 1] 또는 [비활성화 조건 2]에는 사용하지 않는다.
version: 1.0.0
license: MIT
allowed-tools: [Optional] Read Bash Write
metadata:
author: [Optional] your-handle
Skill Name
When to use
- [구체적인 사용 시나리오]
- [구체적인 사용 시나리오]
When NOT to use
- [범위 밖 시나리오]
Workflow
- [단계]
- [단계]
- [경계 사례]는
references/advanced.md를 참고한다.
Examples
- Input: “…” → Output: “…”
Output format
assets/template.md등을 사용한다.
Anti-patterns to avoid
- […]하지 않는다.
폴더 구조
skill_name/
├── SKILL.md # 필수: YAML 프런트매터 + 마크다운 지침
├── scripts/ # 선택: 실행 가능한 보조 스크립트(Python, Bash)
├── references/ # 선택: 필요할 때 로드되는 보조 문맥 자료
├── assets/ # 선택: 출력에 사용되는 파일(템플릿, 리소스)
├── … # 그 밖의 추가 파일 또는 디렉터리
이름 짓기
· 디렉터리 이름은 snake_case를 사용한다.
· Skill 이름은 kebab-case를 사용한다.
· pdf-processor가 아니라 processing-pdfs처럼 동명사형을 선호한다.
· helper, utils, tools, data처럼 일반적인 이름은 피한다.
· claude-*, gemini-*, anthropic-*처럼 벤더 접두어를 붙이지 않는다.
· 외부인이 알아보지 못할 내부 은어를 피한다.
description 필드
description은 라우팅 알고리즘이다. 다른 어떤 부분보다 여기에 더 많은 시간을 써라.
· 무엇을 하는지와 언제 사용해야 하는지를 모두 명시한다.
· 트리거 키워드를 앞쪽에 둔다. 예를 들어 “이 Skill은 …을 돕는다”가 아니라 “커밋 메시지를 생성한다…”처럼 쓴다.
· 과잉 트리거를 막기 위해 언제 사용하면 안 되는지도 포함한다.
· 모델이 Skill을 충분히 호출하지 않는다면 더 강하게, 더 명시적으로 쓴다.
· API에서는 200자 이하, YAML에서는 1,024자 이하를 권장한다. 대부분의 작성자는 약 50단어를 목표로 한다.
다섯 가지 규칙
• 하나의 Skill, 하나의 일. Skill이 하는 일을 한 문장으로 설명할 수 없다면, 그것은 하나의 Skill이 아니라 두 개의 Skill이다. 작성하기 전에 먼저 분해하라.
• description은 인터페이스다. 에이전트는 description을 읽고 어떤 Skill을 선택할지 결정한다. 모호한 description은 결국 사용되지 않는 Skill을 만든다.
• Skills는 의존성이다. 라이브러리처럼 다루라. 버전 관리하고, 버전을 고정하고, PR에서 검토하라. 테스트 없는 Skill은 역량이 아니라 희망사항일 뿐이다.
• 올바른 팀이 올바른 Skill을 소유해야 한다. 도메인 전문가는 도메인 Skill을 소유해야 한다. AI 팀이 조직의 도메인 지식 전체를 처리하는 병목이 되게 해서는 안 된다.
• 에이전트 런타임은 교체 가능하다. Skill을 특정 런타임에 묶지 말라. 이식성은 Skill 가치의 일부다.
품질 원칙
• 먼저 직접 그 작업을 해 보라. 실제 실패는 신호를 만든다. 추측은 잡음을 만든다.
• 규칙만 주지 말고 이유를 주라. 모델은 지시가 왜 존재하는지 이해할 때 경계 사례에도 훌륭하게 일반화한다. 대문자로 “ALWAYS”나 “NEVER”를 쓰고 있는 자신을 발견했다면, 잠시 멈추고 그 이유를 설명해 보라.
• 모든 문장은 자기 자리를 가질 이유가 있어야 한다. 주의할 점, 정확한 명령어, 비즈니스 로직, 안티패턴은 남겨라. 하지만 “항상 출력을 검증하라”처럼 모델이 이미 알고 있는 상투적 문구는 잘라내라.
• 하나의 Skill, 하나의 일. description에서 서로 무관한 기능 사이에 “그리고”가 필요하다면, Skill을 나누어라.
• 지침은 검증 가능해야 한다. 에이전트가 자신이 그 규칙을 따랐는지 판단할 수 없다면, 그 규칙은 너무 모호하다.
• 반복되는 것은 묶어라. 에이전트가 계속 다시 만들어 내는 보조 코드는 scripts/에 들어가야 한다.
해야 할 것과 하지 말아야 할 것
해야 할 것
· 작고 구체적으로 시작하라.
· description 필드에 비대칭적으로 많은 시간을 써라. 그것이 라우팅 알고리즘이다. 항상 무엇을 하는지, 언제 쓰는지, 언제 쓰면 안 되는지를 포함하라.
· 점진적 공개를 신뢰하라.
· 결정론적 작업은 지침으로 쓰지 말고 scripts/에 묶어라.
· Skills를 코드처럼 다루라.
· 기억하라. Skills vs. MCPs가 아니라 Skills + MCPs다.
· 테스트 케이스와 통제된 프로그래밍 방식 평가를 갖추라. 실제 방법은 4장에서 다룬다.
하지 말아야 할 것
· “문서 작업을 돕는다”처럼 모호한 description을 쓰지 말라. 구체적인 동사, 트리거 문구, 사용하지 말아야 할 조건을 사용하라.
· SKILL.md 본문을 5,000단어 넘게 쓰지 말라. 세부 내용은 references/로 옮겨라.
· 경로나 비밀값을 하드코딩하지 말라.
· AGENTS.md에 더 적합한 “항상 X를 하라” 규칙을 Skill 안에 박아 넣지 말라.
· 신뢰할 수 없는 서드파티 라이브러리나 Skill을 스캔 없이 설치하지 말라.
· MCP를 스크립트로 다시 만들려고 하지 말라.
Skill 스멜: 이런 징후가 보이면 수정하라
· 5,000단어를 넘는다. 아마 두 개의 Skill이거나, references/에 들어가야 할 참조 자료일 가능성이 높다.
· 두 도메인 팀이 그 Skill을 소유할 수 있을 것 같다. 아직 제대로 분해되지 않은 것이다. 팀 경계를 기준으로 나누어라.
· 테스트 케이스 세 개를 쓸 수 없다. description이 너무 모호하거나, Skill이 너무 많은 일을 하고 있다.
· 다른 리소스를 전혀 참조하지 않는다. 어쩌면 단순히 시스템 프롬프트에 들어가야 할 긴 지침일 수 있다.
· 계속 “edge cases” 섹션을 추가하고 있다. 각 경계 사례는 자기만의 Skill을 필요로 할 가능성이 높다.
· description이 “a helpful skill for…”로 시작한다. 다시 써라. description은 트리거, 입력, 출력을 명명해야 한다.
평가 커버리지 체크리스트
하나의 Skill은 아래 네 가지 조건을 모두 만족할 때에만 “평가되었다”고 말할 수 있다.
· ☐ Trigger. 긍정 테스트 케이스와 부정 테스트 케이스가 모두 있다. 목표는 90% 트리거 정확도다.
· ☐ Execution. 대표적인 입력 범위 전반에서 올바른 출력이 나온다.
· ☐ Regression. 이 Skill을 추가해도 기존 라이브러리 평가 스위트의 성능이 전혀 떨어지지 않는다.
· ☐ Token budget. 자주 활성화되는 Skill 5~15개와 함께 동시 로딩되어도, 관련 없는 턴의 성능을 저하시키지 않는다.
어느 하나라도 실패하면, 정상 경로 성능이 아무리 좋아도 해당 Skill은 Draft 단계에 머물러야 한다.
배포 체크리스트
· ☐ 프런트매터가 유효하다. 린트 검사를 통과한다.
· ☐ description에 무엇을 하는지 + 언제 쓰는지 + 언제 쓰지 않는지가 포함되어 있다.
· ☐ 스크립트의 단위 테스트가 CI에서 통과한다.
· ☐ 평가 스위트가 CI에서 최소 통과 기준을 만족한다.
· ☐ 보안 스캔이 깨끗하다. 비밀값이나 신뢰할 수 없는 의존성이 없다.
· ☐ description을 작성자가 아닌 다른 사람이 검토했다.
· ☐ 공개 배포라면 여러 도구의 설치 경로를 테스트했다.
· ☐ 해당되는 경우 조직 수준의 관리자 프로비저닝을 업데이트했다.
한 줄짜리 사고 모델
시스템 프롬프트는 본능이다. AGENTS.md는 프로젝트 README다. Tools / MCP는 손이다. RAG는 도서관이다. Skills는 첫날 숙련된 동료가 건네주는 런북이며, AI가 절대 잊지 않는 절차서다.
내일 어디서 시작할 것인가
• 가장 숙련된 실무자를 한 시간 따로 만나라. 그 사람이 정기적으로 수행하는 워크플로 세 가지를 말로 설명하게 하라. 그리고 녹음하라.
• 가장 자주 반복되는 워크플로를 고르라. Skill을 전혀 로드하지 않은 상태에서 직접 프롬프트를 실행해 보라. 에이전트가 어디서 실패하는지 기록하라. 또는 유사한 에이전트에게 맡겨 보라. 원문에는 “Or let an agent similar to ()”처럼 괄호 안 내용이 비어 있는 미완 문장이 있다.
• 녹취록을 바탕으로 SKILL.md를 초안 작성하라. 본문을 쓰기 전에 평가 케이스 세 개를 먼저 작성하라. 두 개는 긍정 케이스, 하나는 부정 케이스로 둔다.
• 읽기 전용 단계로 배포하라. 프로덕션과 유사한 조건에서 테스트하라. 트리거 정확도가 90%를 넘을 때까지 description을 반복 수정하라.
이 과정을 반복하라. 한 번에 하나의 워크플로씩 라이브러리를 만들어라. 첫날부터 LLM에게 Skill 50개를 생성하게 하고 싶은 충동을 참아라.
Appendix B – 사례 연구: 코드로서의 도메인 전문성
리테일 분야의 버티컬 Skill
이 섹션은 이 백서의 실제 적용 예시다. 대형 리테일 기업이 경쟁사와 자신을 차별화하는 조직 지식을 포착하기 위해 Skill 라이브러리를 어떻게 구성할 수 있는지, 그리고 왜 특정 커스텀 에이전트가 아니라 그 라이브러리 자체가 지속 가능한 전략 자산이 되는지를 단계별로 보여 준다. 몇몇 대형 리테일 기업은 아래 아키텍처와 맞아떨어지는 기능을 갖춘 AI 어시스턴트를 이미 공개적으로 설명한 바 있다. 여기서 다루는 것은 특정 벤더 하나의 구현이 아니라, 그 뒤에 놓인 패턴이다.
왜 리테일은 Skills의 대표 사례인가
같은 에이전트 런타임에서 돌아가고, 비슷한 API를 통해 비슷한 데이터에 접근하는 두 리테일 기업이 있다고 해 보자. 그런데 이 두 기업은 완전히 다른 쇼핑 경험을 만들어 낼 수 있다.
리테일 전문성은 역사적으로 AI 시스템이 접근하기 어려웠던 세 곳에 갇혀 있었다. 첫째, 선임 바이어, 머천다이저, 카테고리 매니저의 머릿속. 둘째, 아무도 읽지 않는 30쪽짜리 운영 절차서. 셋째, “이 상품을 저 상품과 함께 추천해도 되는가?”라는 질문의 답이 2023년 어느 Slack 스레드에 남아 있는 식의 흩어진 대화 기록이다.
Skills는 이 지식을 회사의 고객 접점 시스템이 실제로 사용할 수 있는 형식으로 포착한다.
아키텍처는 어떤 모습인가
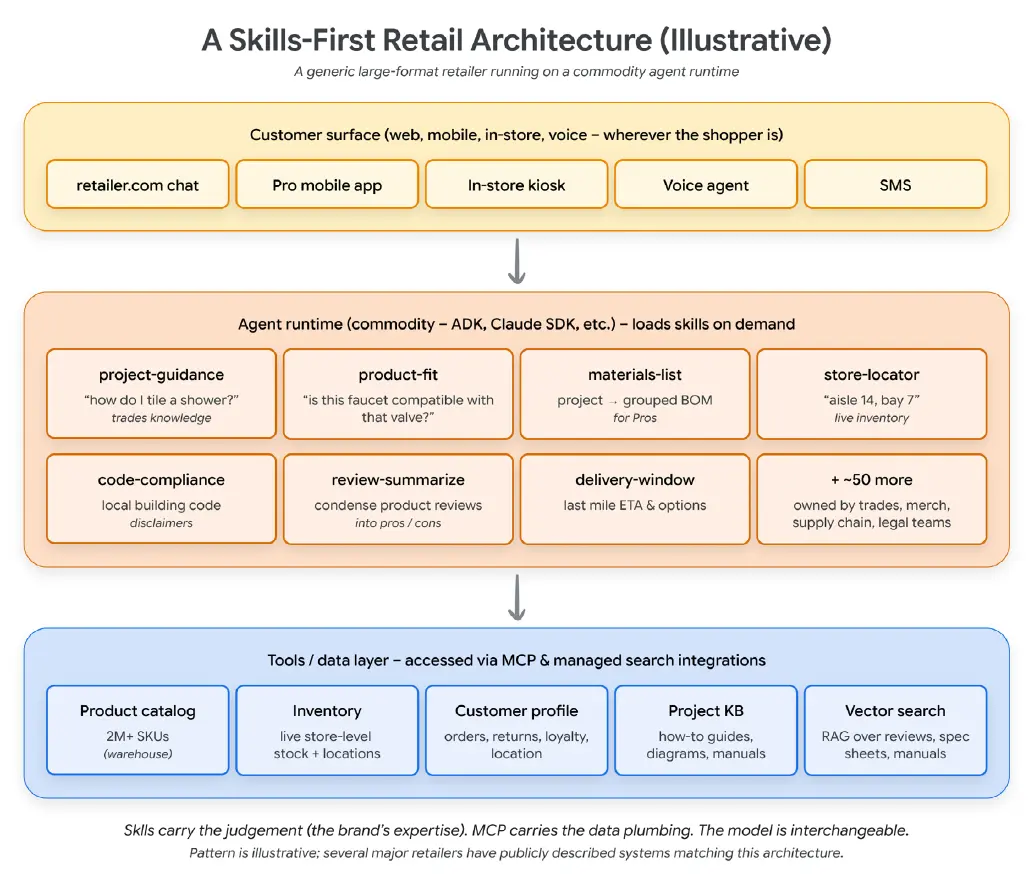
그림 11: Skills-first 리테일 아키텍처 예시. 웹 채팅, 모바일 앱, 매장 키오스크, 음성 에이전트 같은 고객 접점은 머천다이징, 카테고리, 컴플라이언스 지식을 담은 Skills를 로드하는 에이전트 런타임 위에 놓인다. 아래의 도구는 MCP와 관리형 검색 통합을 통해 접근한다.
그림 내 주요 문구 번역: Skills carry the judgment = Skills는 판단을 담는다, MCP carries the data plumbing = MCP는 데이터 배관을 담당한다, The model is interchangeable = 모델은 교체 가능하다.
이 아키텍처는 세 계층으로 구성된다. 첫 번째는 고객 접점 계층이다. 웹사이트 채팅, 모바일 앱, 매장 키오스크, 콜센터의 음성 에이전트가 여기에 해당한다. 각 접점은 얇게 설계된다. 사용자 입력을 런타임으로 전달하고, 런타임이 만든 응답을 보여 주는 역할만 한다.
두 번째는 에이전트 런타임과 오케스트레이터 계층이다. 이 계층은 대화를 유지하고, Skill을 로드하며, 도구를 호출하고, 최종 응답을 조립한다.
세 번째는 데이터와 도구 계층이다. 여기에는 수백만 개의 SKU를 담은 상품 카탈로그, 매장 단위 위치 데이터를 포함한 실시간 재고, 고객 프로필과 주문 이력, 프로젝트 지식 기반, 그리고 리뷰·매뉴얼·사양서에 대한 벡터 검색이 포함된다.
이 백서에서 중요한 것은 가운데 계층이다. 런타임 자체는 범용적이다. Google의 Agent Development Kit, Anthropic의 Claude Agent SDK, 또는 공개 Skills 표준을 지원하는 다른 런타임이면 된다. 그러나 그 런타임에 로드되는 Skills는 해당 리테일 기업의 도메인에 특화되어 있다. 바로 그 Skills가 브랜드의 전문성을 고객에게 전달한다.
예시 Skill 라이브러리
그렇다면 실제 라이브러리는 어떤 모습일까? 아래는 대형 홈 인프루브먼트 리테일 기업이 유지할 법한 대표적인 Skill 묶음이다. 각각은 하나의 폴더다. 각각은 단일 소유자를 가진다. 각각은 4장에서 설명한 패턴을 활용한 자기만의 평가 스위트를 가진다. 이 Skill들을 합치면, 회사가 고객을 어떻게 응대하고 도와야 하는지에 대한 작동 가능한 기억이 된다.
· project-guidance. “샤워실 타일을 어떻게 붙이면 되나요?” 같은 모호한 질문을 단계별 계획으로 바꾸는 현장 기술자의 지식을 인코딩한다. 여기에는 타일을 붙이기 전에 바탕면을 방수 처리해야 한다는 구조적 의존성, 설치 전에 절단이 먼저라는 작업 순서, 그리고 흔한 실수에 대한 경고가 포함된다. 소유자는 현장 기술 지식 팀이다. 권한 단계는 읽기 전용이다.
· materials-list. 음성, 텍스트, 또는 일부 품목만 있는 목록 형태의 프로젝트 설명을 받아, 그룹화된 자재 명세서로 만든다. 이때 시공업자가 잊기 쉬운 품목까지 포함한다. 소유자는 Pro 머천다이징 팀이다. 권한 단계는 초안 전용이다. 고객이 구매하기 전에 직접 검토해야 한다.
· review-summarize. 긴 제품 리뷰를 장점, 단점, 일반적인 사용 사례로 압축한다. 고객이 특정 제품의 실제 사용 경험을 묻는 경우 트리거된다. 소유자는 개인화 팀이다. 권한 단계는 읽기 전용이다.
· delivery-window. 고객 위치, 매장 재고 상황, 회사의 화물 네트워크를 바탕으로 라스트마일 배송 옵션과 예상 도착 시간을 계산한다. 소유자는 풀필먼트 팀이다. 권한 단계는 읽기 전용이다.
· return-policy. 회사의 반품 규칙을 인코딩한다. 여기에는 특별 주문 품목, 위험물, 맞춤 절단, 계약 가격 등 수십 가지 예외가 포함된다. 소유자는 고객 서비스 팀이다. 권한 단계는 읽기 전용이다. 환불 발행처럼 실행 허용 단계로 승격하려면, 훨씬 더 엄격한 검토를 통과한 두 번째 Skill이 필요하다.
각 Skill은 독립적으로 검토하고, 테스트하고, 배포할 수 있을 만큼 작다.
같은 고객 질의는 라이브러리를 어떻게 통과하는가
고객이 이렇게 묻는 상황을 생각해 보자. “아이들 욕실을 리모델링하고 싶은데, 뭐가 필요할까요?”
세션이 시작되면 런타임은 모든 Skill의 L1 description을 로드한다. 각 description은 약 30~80토큰이며, 전체로는 약 2KB 수준이다. 런타임은 project-guidance가 이 요청과 맞는다고 판단하고 해당 Skill 본문을 로드한다. 그러면 이 Skill은 리모델링 단계의 개요를 만든다. 고객이 이어서 배송을 묻는다면 delivery-window Skill이 로드된다. 특정 품목의 반품 가능 여부를 묻는다면 return-policy Skill이 로드된다. 대화가 다른 주제로 이동하면 이전 Skills는 컨텍스트에 남아 있을 수도 있고, 해제될 수도 있다.
여기서 일어나지 않는 일에 주목해야 한다. 모든 리모델링 시나리오를 학습한 거대한 단일 “리모델링 어시스턴트” 에이전트는 없다. 각 전문성 조각은 대화가 그 지점에 도달했을 때에만 컨텍스트로 들어온다. 활성 컨텍스트는 작게 유지된다. 그러나 사용할 수 있는 역량은 사실상 제한 없이 확장된다.
소유권: 누가 어떤 Skill을 작성하는가
리테일 기업이 Skill 라이브러리에 대해 내려야 할 가장 중요한 거버넌스 결정은 각 Skill의 소유자가 누구인가다. 원칙은 단순하다. 이미 해당 전문성을 소유하고 있는 팀에게 Skill 소유권을 분산해야 한다.
| Skill 계열 | 소유 팀 | 이유 |
| project-guidance, product-fit | 현장 기술 지식 팀 / 카테고리 관리 팀 | 이 팀들이 머천다이징 규칙과 현장 기술 규칙을 보유하고 있으며, 이미 주 단위로 해당 규칙을 수정하고 있다. |
| materials-list | Pro 머천다이징 팀 | Pro 고객군에 특화된 BOM 로직은 Pro 팀이 소유한다. |
| delivery-window | 매장 운영 / 풀필먼트 팀 | 실시간 재고와 화물 규칙은 계속 바뀐다. 이를 처리하는 팀이 Skill도 소유해야 한다. |
| review-summarize | 개인화 / 데이터 사이언스 팀 | 기반이 되는 NLP와 고객 피드백 신호에 가장 가까운 팀이다. |
읽기 / 초안 / 실행 사다리
두 번째 거버넌스 결정은 각 Skill이 무엇을 할 수 있도록 허용할 것인가다. 이는 4장에서 다룬 단계 모델을 리테일 사례에 적용한 것이다.
| 단계 | 역량 | 검토 | 예시 |
| Read-Only / 읽기 전용 | 데이터를 가져오고, 조회하고, 설명할 수 있다. 상태는 변경할 수 없다. | 도메인 팀 승인 | review-summarize, store-locator, project-guidance |
| Draft-Only / 초안 전용 | 사람 검토용 콘텐츠를 만들 수 있다. 발송하거나 확정할 수는 없다. | 도메인 팀 + 형식 소유자 | draft-customer-email, materials-list |
| Action-Allowed / 실행 허용 | 실제 시스템에서 되돌릴 수 없는 작업을 실행할 수 있다. | 도메인 팀 + 보안/컴플라이언스 + 임원 승인 | issue-refund, send-customer-message, reserve-inventory |
이 구조는 보안팀에게도, 언젠가 찾아올 규제기관에게도 훨씬 더 방어 가능하다. 그 대안은 학습 내용과 시스템 프롬프트가 만들어 내는 결과에 따라 무엇이든 할 수 있는 블랙박스 에이전트이기 때문이다.
왜 이것은 커스텀 에이전트보다 경쟁하기 어려운가
경쟁사와 우리 리테일 기업이 모두 같은 범용 에이전트 런타임 위에서 돌아간다고 해 보자. 실제로도 그럴 가능성이 높다. 런타임은 이미 범용재화되고 있기 때문이다. 그렇다면 런타임을 따라잡는 것은 어렵지 않다. 하지만 Skill 라이브러리는 회사가 오랜 시간 축적한 패턴을 인코딩한다. 이것이 이 백서의 핵심 전략적 주장이다.
커스텀 에이전트에 크게 투자하면서 Skill 라이브러리를 소홀히 하는 리테일 기업은, 경쟁사도 곧 공짜로 접근할 수 있게 될 스택의 일부에 투자하는 셈이다. 반대로 범용 런타임 위에서라도 Skills에 투자하는 리테일 기업은 회사가 실제로 알고 있는 것을 담은 지속 가능한 자산을 구축하는 것이다.
콜드 스타트: 실제로 어디서 시작할 것인가
유용한 연습 방법이 있다. 팀에서 가장 경험 많은 실무자를 한 시간 따로 만나, 그 사람이 정기적으로 수행하는 워크플로 세 가지를 말로 설명하게 하라. 그리고 그 대화를 녹음하라. 그 녹취록은 거의 말 그대로 세 개의 Skill에 대한 첫 초안이다. Skills가 등장하기 전에는 이런 종류의 작업 결과를 둘 분명한 자리가 없었다. 이제는 있다.
Ling, G., Zhong, S., & Huang, R. (2026). 「Agent Skills: A Data-Driven Analysis of Claude Skills for Extending Large Language Model Functionality」. arXiv:2602.08004. 주요 마켓플레이스에 공개 등록된 40,285개 Skill 분석.
Google Cloud Blog. (2026년 4월). 「Level Up Your Agents: Announcing Google’s Official Skills Repository」. 저장소: https://github.com/google/skills. Antigravity 및 표준을 따르는 코딩 에이전트에서 npx skills install github.com/google/skills로 설치 가능.
Endnotes
https://github.com/anthropics/skills/tree/main/skills/skill-creator
https://hermes-agent.nousresearch.com/docs/user-guide/features/skills
https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills
https://vercel.com/blog/agents-md-outperforms-skills-in-our-agent-evals
https://latitude.so/blog/agent-first-comparison-guide-vs-braintrust
Liu, Zhao, Shang, and Shen (2026), Claude Code v2.1.88 역공학 분석. Companion site: ccunpacked.dev
Liu et al., “Lost in the Middle” (TACL 2024). https://arxiv.org/abs/2601.06112
Chroma Research, “Context Rot” (2025). https://arxiv.org/abs/2601.17087
https://developers.googleblog.com/en/developers-guide-to-building-adk-agents-with-skills/
https://github.com/anthropics/skills/blob/main/skills/skill-creator/SKILL.md
Google. (2026). Agents CLI: Google Cloud에서 ADK 에이전트 개발 생애주기를 통합하는 CLI. https://google.github.io/agents-cli/. Source repository: https://github.com/google/agents-cli. 이 프레임워크는 Google Cloud 위에 구축된 에이전트를 위해 scaffold, build, eval, deploy, publish, observability를 포괄하는 7개 Skill을 제공하며, Agent Skills 표준을 지원하는 어떤 코딩 에이전트에도 연결되도록 설계되었다.
Google Cloud Blog. (2026년 4월). Level Up Your Agents: Announcing Google’s Official Skills Repository. https://cloud.google.com/blog/topics/developers-practitioners/level-up-your-agents-announcing-googles-official-skills-repository. Repository: https://github.com/google/skills. Antigravity 및 표준 호환 코딩 에이전트에서
npx skills install github.com/google/skills로 설치 가능.Google Developers Blog. (2026년 3월). Closing the knowledge gap with agent skills. https://developers.googleblog.com/closing-the-knowledge-gap-with-agent-skills/. Gemini API developer skill이 117개 프롬프트의 SDK 코드 생성에서 Gemini 3.1 Pro의 성능을 28.2%에서 96.6%로 향상시켰다고 보고한다. Source skill: https://github.com/google-gemini/gemini-skills.
Anthropic. (2025–2026). anthropics/skills — Agent Skills 공개 저장소. https://github.com/anthropics/skills. Skills 표준의 Anthropic 참조 구현과 문서(docx, pdf, xlsx, pptx), MCP 서버 구축, Skill 생성 자체를 위한 예시 Skill을 포함한다.
Stripe. (2026). stripe/ai — Stripe로 AI 기반 제품과 비즈니스를 구축하기 위한 원스톱 저장소. https://github.com/stripe/ai. API 선택, Connect 설정, billing, 보안을 위한 stripe-best-practices skill(skills/stripe-best-practices/SKILL.md)을 포함하며 Stripe가 게시·유지보수한다.
Microsoft. (2026). microsoft/skills — Coding Agents를 SDK에 grounding하기 위한 Skills, MCP servers, Custom Agents, Agents.md. https://github.com/microsoft/skills. Azure SDK와 Microsoft Foundry에서 코딩 에이전트를 grounding하기 위한 Microsoft 공식 Skill 모음.
VoltAgent. (2026). awesome-agent-skills — 공식 개발팀과 커뮤니티가 만든 1000개 이상의 agent skills 선별 모음. https://github.com/VoltAgent/awesome-agent-skills. Anthropic, Google Labs, Vercel, Stripe, Cloudflare, Netlify, Trail of Bits, Sentry, Expo, Hugging Face, Figma 등 공식 Skill과 커뮤니티 Skill을 함께 제공한다. Claude Code, Codex, Antigravity, Cursor, GitHub Copilot, OpenCode, Windsurf와 호환된다.
Skills Marketplace. (2026). https://skillsmp.com. 공개 GitHub 저장소에서 수집한 120만 개 이상의 Skill을 모은 독립 커뮤니티 집계 마켓플레이스. 의미 검색, 직업 필터링, 최소 품질 지표(별 2개 기준)를 제공한다. 마켓플레이스 운영자는 설치 전에 커뮤니티 Skill을 직접 점검할 것을 명시적으로 권장한다.
Osmani, A. (2026). addyosmani/agent-skills — AI 코딩 에이전트를 위한 프로덕션급 엔지니어링 Skill. https://github.com/addyosmani/agent-skills.
댓글
GitHub 계정으로 의견을 남길 수 있습니다. 댓글은 GitHub Discussions에 저장됩니다.