Lee Boonstra의 2026년 5월 백서 Vibecode in the Age of Agentic Development를 한국어로 옮기고, 블로그에서 읽기 쉽도록 제목 체계와 코드 스니펫, 체크리스트 형식을 정리한 글입니다.
원문의 논지와 순서는 유지하되, 긴 번역 원고를 그대로 붙여 넣는 대신 핵심 요약, 읽는 법, 접기 가능한 원문 목차를 앞에 두었습니다.
이 글의 핵심 문장은 간단합니다. 바이브 코딩은 프로토타입을 빠르게 만들 수 있지만, 프로덕션 개발은 스펙, 테스트, 평가, 정책 서버, 샌드박스, Human-in-the-Loop로 통제해야 한다는 것입니다.
먼저 읽을 핵심
- AI 코딩 시대의 병목은 코드 작성에서 스펙 작성, 검토, 통합, 검증으로 이동한다.
- 스펙은 채팅창에 길게 붙여 넣는 문서가 아니라, 저장소 안에서 버전 관리되는 실행 가능한 청사진이어야 한다.
- BDD, Gherkin, Markdown + YAML 조합은 에이전트가 추측하지 않도록 만드는 실무적 장치다.
- MCP는 도구 통합을 반복해서 만들지 않게 해 주는 공통 인터페이스다.
- AI가 생성한 코드가 많아질수록 코드 리뷰, 테스트, 평가, 보안 게이트도 자동화되어야 한다.
- 프로덕션급 에이전트에는 샌드박싱, 정책 서버, 컨텍스트 정화, HITL 같은 제로 트러스트 개발 경계가 필요하다.
이 글을 읽는 방법
- 실무 적용만 빠르게 보고 싶다면: 스펙 주도 개발, SDD, 사용 사례별로 다른 프롬프트, 제로 트러스트 개발을 먼저 읽으면 됩니다.
- 팀 운영 관점에서 보고 싶다면: 팀 문화와 프로세스의 진화, 코드 리뷰, 레포를 감시하는 에이전트 배포하기가 핵심입니다.
- 보안과 평가 관점에서 보고 싶다면: 정책 서버, 컨텍스트 위생과 프롬프트 정화, 평가를 중심으로 읽으면 됩니다.
원문 목차 펼쳐 보기
- 서론
- 스펙 주도 개발, SDD
- 좋은 스펙
- 어떤 형식을 사용할 것인가?
- 행동 주도
- 지시사항은 어디에 두어야 하는가?
- 사용 사례별로 다른 프롬프트
- MCP: 하나의 통합, 모든 프레임워크
- MCP 서버 구축하기
- MCP 클라이언트 연결하기
- 팀 문화와 프로세스의 진화
- 코드 리뷰
- 레포를 감시하는 에이전트 배포하기
- 지속 가능성
- 제로 트러스트 개발: 안전망 구축하기
- 가드레일 구현하기
- 샌드박싱
- Human-in-the-Loop
- AI가 생성한 테스트 커버리지
- 평가
- 정책 서버
- 컨텍스트 위생과 프롬프트 정화
- 요약
- Endnotes
서지와 감사의 말
- 제목: 바이브 코딩 시대의 스펙 주도 프로덕션급 개발
- 부제: 확장 가능한 워크플로와 팀 진화를 위한 청사진: 바이브 프로토타입에서 프로덕션 현실로
- 저자: Lee Boonstra
- 발행: 2026년 5월
- 콘텐츠 기여 및 검토: Elia Secchi, Antonio Gulli
- 디자이너: Michael Lanning
서론
지난 1년 사이 Google 소프트웨어 엔지니어의 일상은 완전히 180도 앞으로 뒤집혔다. 2024년 초와 그 이전에는 개발자 API와 문서를 파고들고, 코드 한 줄 한 줄을 직접 실행해 보며, Python에서는 substring in string을 쓰는지, string.includes를 쓰는지, 아니면 string.contains를 쓰는지 확인하는 데 상당한 시간을 썼다. 코드가 완성된 뒤에는 기능하는 코드와 원래 의도 사이의 불일치를 디버깅하고 해결하는 데 많은 노력이 들어갔다.
오늘날 개발은 워프 속도로 움직인다. 팀들은 이제 Antigravity1나 Gemini CLI2 같은 코딩 에이전트를 사용한다. 이들은 단순히 텍스트를 제안하는 것이 아니라 실제로 도구를 사용하고 작업을 실행한다. AI 코딩 에디터는 문서화가 잘 된 코드 수천 줄을 빠르게 쏟아낼 수 있다. 마치 잠도 자지 않고 불평도 하지 않는 인턴 부대가 고용된 듯한 느낌이다.
하지만 함정이 있다. 속도는 과속 기어에 들어갔지만, 속도의 착시는 실제로 존재한다. 버그 대 코드 비율은 여전히 문제다. AI가 코드를 훨씬 더 빠르게 작성하는 만큼, 잠재적 실수도 전례 없는 속도로 만들어 낼 수 있기 때문이다. 그러나 구현이 더 이상 주된 병목이 아니므로, 같은 시간 안에 어떤 인간보다도 포괄적인 테스트 커버리지를 AI로 작성하게 할 수 있다. 이는 코드에 대한 신뢰를 높이는 강력하고 프로그래밍 가능한 방식이며, 뒤에서 자세히 다룬다.
더 나아가 AI의 잠재력은 구현을 훨씬 넘어선다. AI는 시스템 설계, 스펙 작성, 로드맵 계획, 결과 분석에서도 뛰어나다. 병목은 이 작업물을 통합하고 검토해야 하는 인간 쪽, 즉 더 하류의 단계로 이동했지만, 이를 처리할 도구는 이미 존재한다.
“바이브 코딩”은 “바이브 인 프로덕션”이 아니다.
“바이브 코딩”은 엄격한 수동 코딩이 아니라, “바이브” 또는 고수준 의도에 따라 AI를 사용해 코드를 빠르게 생성하는 방식을 가리킨다. 그러나 반드시 분명히 해야 할 점이 있다. “바이브 코딩”은 “바이브 그대로 프로덕션에 올리기”가 아니다. 우리는 AI 에이전트의 잠재력을 최대한 활용하지만, 검증되지 않은 AI 출력에 의존하는 것이 아니라 프로덕션급 신뢰성을 보장하기 위해 모든 것을 의도하고 통제한다.
엔터프라이즈 환경에서 이 “바이브”는 에이전트형 AI를 활용한 개발이라고 부른다. 표준 생성형 AI가 똑똑한 자동완성처럼 작동한다면, 에이전트형 AI는 하이브리드 팀원처럼 작동한다. 언어 모델을 사용해 생성하고, 즉 “두뇌”를 사용하며, 도구를 사용해 워크플로에 통합된다. 즉 “손”을 갖고 있다. 에이전트형 AI는 추론하고, 스펙이나 테스트 케이스를 작성하고, 브라우저를 사용해 UI를 테스트하고, Git에서 코드를 커밋하고 병합할 수 있다.
그러나 개발이 개인적 실험에서 팀 기반 프로덕션 규모로 이동하면, 점심 전까지 코드 1,000줄을 쓰는 것과 소프트웨어를 출시하는 것은 같은 일이 아니라는 사실이 명확해진다.
에이전트가 “환각”을 일으킬 때, 다시 말해 모델이 사실이 아닌 것을 자신 있게 지어낼 때, 그것은 버그 하나만 만드는 것이 아니다. 기능적으로는 망가졌지만 “바이브에는 맞는” 로직 수천 줄을 만들어 낼 수 있다. 인간 리뷰어가 AI가 생성한 풀 리퀘스트, 즉 작업이 실제로 반영되기 전에 팀원에게 검토를 요청하는 디지털 요청의 바다에 빠져 있다면, 작성 속도는 아무 의미가 없다. 프로세스는 실제로 더 빨라진 것이 아니다. 나중에 분류해야 할 “무언가” 더 큰 더미를 만들고 있을 뿐이다.
다행히 개발 프로세스를 보호하는 방법은 있다. 하지만 중요한 것은 중간에 가서가 아니라 처음부터 이 기법들을 사용해야 한다는 점이다. 이 백서에는 바이브 코딩 시대에 프로덕션용 코드를 개발하는 방법, 코드를 보호하는 방법, 팀 문화를 바꾸는 방법에 이르는 일련의 기법이 담겨 있다.
스펙 주도 개발, SDD
전통적인 소프트웨어 엔지니어링 세계에서 개발자는 “코드 우선”으로 배웠다. 모호한 아이디어가 떠오르면 에디터를 열고 무언가 작동할 때까지 타이핑했다. 그러나 에이전트형 AI 시대에는 일상적인 활동이 극적으로 바뀌었다. 이제 대부분의 시간은 고품질 스펙, 즉 AI에게 정확히 무엇을 만들어야 하는지 알려 주는 상세한 기술 지시사항을 작성하는 데 쓰인다.
이 새로운 워크플로에서 개발자의 역할은 전통적인 코더라기보다 기술 아키텍트에 가깝다. 여기서 중요한 부분은 이것이다. 코드는 이제 폐기 가능하다. 탄탄한 스펙을 작성했다면 전체 코드베이스는 반복해서 다시 생성될 수 있다. 에이전트에게 프로젝트 전체를 Python에서 JavaScript로 하루 오후 만에 전환하라고 지시할 수도 있다. 코드가 폐기 가능해졌기 때문에 코드에 대한 감정적 애착도 예전 같지 않다. 세미콜론 하나를 디버깅하느라 12시간을 쓰지 않았기 때문에 요구사항이 바뀌면 코드를 버리고 다시 시작하는 데 두려움이 없다.
Antigravity나 Gemini CLI 같은 코딩 에이전트는 대규모 언어 모델, 즉 LLM을 “두뇌”로 사용해 추론하고, 도구를 “손”으로 사용해 작업을 실행한다. 두뇌에게 “청사진”이 아니라 “바이브”만 주면, 두뇌는 추측한다. 그리고 엔터프라이즈 소프트웨어에서 추측은 “Rogue Agent”, 즉 통제에서 벗어난 에이전트 사고가 발생하는 방식이다.
좋은 스펙
그렇다면 프로덕션급 청사진은 어떤 모습이어야 할까? 좋은 스펙은 아키텍처상의 북극성이다. 이는 “컨텍스트 단편화”를 막아 준다. 컨텍스트 단편화란 AI가 오래된 파일 스냅샷을 보고 있기 때문에 이야기의 줄거리를 잃기 시작하는 현상으로, 디지털판 “전화 게임”과 같다. 좋은 스펙을 다듬는 데 AI를 사용할 수도 있다. 본질적으로 AI를 공동 저자 또는 스펙 편집자/검토자로 쓰는 것이다. 일반적으로 스펙은 코드베이스 안에 저장된다. 예를 들어 specs/ 폴더 안에 Markdown 또는 YAML 파일로 저장한다. 이 스펙은 인간과 AI 모두에게 진실의 원천 역할을 한다.
어떤 형식을 사용할 것인가?
Ouyang 등(2026)의 연구 “SkCC: Portable and Secure Skill Compilation for Cross-Framework LLM Agents”3는 LLM 에이전트가 지시사항의 형식에 극도로 민감하며, 일반적인 최적화되지 않은 Markdown 파일을 사용할 때 성능이 최대 40%까지 떨어질 수 있음을 보여 준다. 이를 해결하기 위해 연구자들은 **SkCC(Skill Compiler)**를 개발했다. SkCC는 단일 소스 지시 파일을 모델에 최적인 대상 형식으로 10밀리초 이내에 자동 컴파일하는 초고속 도구다.
Gemini를 사용하는 팀의 경우, 이 논문은 절대적으로 가장 좋은 형식 전략이 Markdown + 조건부 YAML의 하이브리드 접근임을 보여 준다. Gemini는 깔끔한 Markdown 헤더를 사용해 주의력을 고정하지만, 구조화된 설정이나 중첩 깊이가 3을 초과하는 데이터 스키마에서는 YAML로 전환할 때 성능이 최고점에 도달한다. 데이터에 따르면 깊게 중첩된 설정의 경우 YAML은 51.9%의 파싱 정확도를 달성한 반면, JSON은 43.1%, XML은 33.8%에 그쳤다.
깊게 중첩된 스펙은 YAML로 렌더링하고, 서술형 지시사항은 Markdown에 유지함으로써 개발자는 무거운 JSON 입력과 관련된 추론상의 “형식세”를 우회할 수 있다. 그 결과 Gemini는 최대 정확도와 최적의 토큰 경제성을 유지하며 작동한다.
행동 주도
행동 주도 개발(BDD) 스펙은 모호하고 애매한 인간의 아이디어를 AI 에이전트가 추측 없이 구축할 수 있는 정밀한 아키텍처 설계로 바꾸는 궁극적인 도구다. 핵심적으로 BDD는 실제 코드를 작성하기 전에 사용자의 관점에서 시스템이 정확히 어떻게 동작해야 하는지를 평이하면서도 구조화된 자연어로 설명하는 소프트웨어 개발 방법론이다.
BDD 스펙은 Gherkin4이라는 표준 문법을 사용한다. Gherkin은 단순하고 선언적인 템플릿, 즉 Scenario / Given / When / Then에 의존한다. 이 구조는 LLM이 상태 > 행동 > 결과의 관점으로 생각하도록 강제하며, “바이브 코딩”을 완전히 제거하고 에이전트를 엄격한 궤도 위에 유지한다.
새 프로젝트 생성을 위한 좋은 스펙에는 다음이 포함된다.
- 전체 기술 설계: “로그인 페이지를 만들어라”라고만 말하지 말라. 조각으로 나누라. 요구사항, 데이터베이스 스키마, 즉 데이터 구조, 그리고 API 스펙, 즉 소프트웨어의 여러 부분이 서로 대화할 수 있게 하는 “계약”을 다루라.
- 시각 자료: 다이어그램과 구체적인 도구 및 라이브러리 목록, 그리고 버전 번호를 포함하라.
- 배경 정보: 에이전트에게 “무엇” 뒤에 있는 “왜”를 제공하라. 이는 에이전트가 앞을 내다보는 데 도움이 된다. 에이전트는 앞으로 필요할 가능성이 높은 단계도 알게 된다.
- 시나리오: 좋은 상태는 무엇인지, 잘못된 상태는 무엇인지, 그리고 경계 사례를 포함하라.
대규모 언어 모델은 데이터 구조를 그대로 해석하지 않는다. 모델은 토큰화된 텍스트를 처리한다. 전송하는 모든 문자는 토큰으로 분해되고, 모든 토큰은 예산, 시간, 컨텍스트 용량을 소비한다. 결국 프로덕션급 스펙을 작성한다는 것은 토큰화를 엄격한 물리적 제약으로 취급한다는 뜻이다. 전송하는 모든 문자, 줄바꿈, 들여쓰기 공백이 개발 예산과 시스템 지연 시간으로 직접 이어지기 때문이다.
Gemini로 구동되는 Google Antigravity 같은 에이전트 플랫폼은 프리뷰 기간 동안 매우 넉넉한 컨텍스트 윈도우와 내장 요율을 제공하지만, 여전히 근본적으로는 underlying 모델의 토큰 물리학에 묶여 있다. 깊게 중첩된 YAML 블록 안의 불필요한 공백 하나, 반복적인 Given / When / Then 지시 하나가, 에이전트가 애플리케이션을 반복적으로 구성하고 테스트하고 수정하는 다중 턴 추론 루프에서 처리 사이클과 어텐션 헤드 용량을 소비한다.
따라서 /specs 폴더를 단순한 문서가 아니라, 인간이 읽기 쉬운 Markdown과 매우 표적화된 평평한 YAML 블록을 균형 있게 결합한 날렵한 컴파일된 지시 집합으로 취급해야 한다. 그렇게 하면 추론의 “형식세”를 제거하고 AI 에이전트를 엄격하고 비용 효율적인 레일 위에서 작동하게 할 수 있다.
팁
나는 기술 설계를 Google Docs에 작성하는 경우가 많다. 아키텍처 계획을 여러 사람이 읽고 검토하게 한다. 이제 이것은 그 어느 때보다 중요하다. AI가 이미 망가진 코드 수천 줄을 생성한 뒤에야 발견하는 것보다, 인간이 설계상의 논리 결함을 먼저 잡아내는 편이 훨씬 낫기 때문이다. 검토가 끝나면
File > Download > Markdown을 사용해 Markdown으로 내려받고, 그 파일을 작업공간의specs/폴더에 추가한다.
지시사항은 어디에 두어야 하는가?
스펙 주도 개발(SDD)을 실천하려면 코딩 도구가 지시사항을 어떻게 소비하는지 이해해야 한다. 지시사항은 단 한 곳에만 쓰이는 것이 아니다. 방대한 100쪽짜리 시스템 설계 문서를 채팅 창에 그대로 쏟아 넣으면 단기 컨텍스트 예산을 빠르게 소진하고, 지연 시간을 늘리며, 컨텍스트를 단편화한다. 이런 스펙은 여러 위치에 둘 수 있다.
1. 채팅 인터페이스: 짧게 유지되는 세션별 공간
IDE 안의 일시적 대화 입력창, 예를 들어 Gemini 사이드 패널이나 터미널 인터페이스는 활성 개발자 세션과 함께 존재한다. 채팅 인터페이스는 순수하게 고수준 오케스트레이션과 즉각적인 피드백 루프에만 사용하라.
예:
1 | specs/payment_retry.md의 설계를 검토하고 Scenario 3에 정의된 실패 단위 테스트를 생성하라. |
2. 스펙 폴더: 작업별로 버전 관리에 포함되는 공간
스펙 폴더는 저장소에 직접 체크인되는 정적 폴더다. 기술 설계, BDD 시나리오, API 계약, 구조적 YAML 스키마를 저장한다. 에이전트는 이 디렉터리를 동적으로 인덱싱하여 수동 프롬프트 채워 넣기 없이 코드를 구축하고 검증한다.
1 | ./my-app/specs/my_spec.md |
3. Agent Skills: 재사용 가능하고 기능/행동 중심적인 공간
Skills는 특화된 트리거 기반 워크플로를 담은 구조화된 Markdown 파일이다. Skills는 저장소 어디에나 있을 수 있지만, Antigravity 작업공간 관리자가 인식하려면 지정된 .agent 디렉터리에 저장해야 한다. Skills는 코드 변경이 감지되면 CHANGELOG.md를 자동으로 유지하는 것처럼 반복 가능한 엔지니어링 습관을 에이전트에게 가르친다.
1 | ./my-app/.agent/skills/docs-maintenance/SKILL.md |
이런 skills 폴더에는 Skill이 사용할 데이터 자산이나 스크립트도 포함될 수 있다.
4. 시스템 프롬프트: 전역적이고 정체성 중심적인 공간
이곳은 AI가 특정 엔지니어링 DNA를 학습하는 장소다. Gemini CLI와 Google Antigravity는 모두 컨텍스트 파일을 계층적으로 스캔하고 연결한다. 즉 사용자 지정 지시사항은 전역 오버라이드에서 로컬 프로젝트 설정까지 층층이 쌓인다.
전역 프로필: 이 파일은 홈 설정 디렉터리, 예를 들어 ~/.gemini/GEMINI.md에 있다. 여기서 AI는 개인의 선호와 더 잘 정렬된다. 프로젝트와 무관하게 보편적인 페르소나, 기본 스타일, 핵심 원칙을 정의한다.
공유 멀티 도구 설정, AGENTS.md: 팀이 여러 AI 클라이언트를 사용하는 경우 지시사항 단편화를 방지하기 위해 생태계는 AGENTS.md를 지원한다. 이는 도구 간 공유되는 기반 역할을 하고, 로컬 GEMINI.md 파일은 Google 특화 설정에 대해 가장 높은 우선순위를 유지한다.
1 | ./my-app/.agents/AGENTS.md |
프로젝트 스펙: 이 파일은 프로젝트 루트 디렉터리, 예를 들어 ./my-app/.gemini/GEMINI.md에 있다. 이것이 프로젝트의 DNA다. CLI 에이전트는 이 파일을 자동으로 감지하고 읽으며, 그 규칙을 우선한다.
사용 사례별로 다른 프롬프트
스펙을 코드로 바꾸는 방법은 하나만 있는 것이 아니다. 이를 여러 실행 모드로 나눌 수 있으며, 각 모드에는 다른 사고방식이 필요하다.
1. 프로젝트 생성: 아키텍트
이 모드에서는 처음부터 스캐폴딩을 수행한다. 즉 프로젝트의 골격을 만든다. YOLO 모드는 금지다. 에이전트에게 즉시 코딩하지 말라고 명시적으로 프롬프트해야 한다. 먼저 폴더 구조와 기술 스택을 제안하고 확인을 받게 해야 한다. 프롬프트에는 테스트, 문서, 로깅 생성도 포함해야 한다. 로깅은 앱이 무엇을 하고 있는지 기록하는 디지털 “블랙박스”다.
모든 라이브러리에 버전 번호를 포함하라. 그렇지 않으면 에이전트는 자신의 “지식 컷오프”, 즉 학습 데이터가 끝난 날짜가 과거였기 때문에 오래된 도구 버전을 제안할 수 있다.
2. 기능 생성: 빌더
이 모드에서는 기존 코드베이스 위에 기능을 구현한다. 에이전트에게 기존 스타일을 맞추라고 지시하라. 여기에는 이름 짓기 패턴과 코드의 오류 처리 방식이 포함된다. 여러 파일을 수정할 때는 변경사항을 수동으로 확인해야 한다. 에디터 안에서 정확히 어떤 줄이 추가되거나 제거되는지 보여 주는 목록인 Diff를 보는 것이 중요하다.
3. 버그 수정: 포렌식 전문가
무언가 고장 났을 때는 포렌식 모드가 필요하다. 목표는 근본 원인 분석과 외과적 수리다. 증상 프롬프팅(“버튼이 작동하지 않아요”)에서 증거 프롬프팅(“gcloud logging read 'textPayload:ERROR' --limit 5로 가져온 로그에서 403 오류가 나타났습니다”)으로 전환하라. Git용 gh 명령 같은 커맨드라인 버전 관리 도구를 사용해 코드 버전을 비교하라. 그런 다음 흐름을 설명하라.
1 | 요청이 Load Balancer에 도달함 -> Auth가 헤더를 제거함 -> Pod가 실패함 |
팁
때때로 코딩 에이전트는 변수 이름 변경을 제안한다. 변수 이름 변경 자체는 허용될 수 있지만, 복잡성을 피하기 위해 버그 수정의 일부가 아니라 별도의 작업으로 수행해야 한다.
항상 먼저 버그를 재현하기 위한 실패 단위 테스트 또는 curl 명령, 즉 URL로 데이터를 보내는 방법을 요청하라. 이 테스트 케이스를 코드베이스에 보관하여 버그가 다시 돌아오지 않게 하라. 에이전트가 오직 근본 원인만 수정해야 한다는 엄격한 제약을 설정하라. 관련 없는 코드를 “정리”해서는 안 된다. 그것은 리뷰 과정을 복잡하게 만들기 때문이다.
엔드투엔드(E2E) 테스트와 문제 해결을 한 단계 끌어올리기 위해 Antigravity 같은 도구는 내장 브라우저를 제공한다. 이를 통해 에이전트는 자율적으로 localhost를 실행하고, 실제 사용자 인터페이스와 상호작용하며, 시각적 수정을 실시간으로 검증할 수 있다. 내부적으로 Antigravity는 완전히 자동화된 네이티브 Chrome 인스턴스를 오케스트레이션하여 이러한 프런트엔드 작업을 실행, 기록, 검증한다.
중요한 점은 무단 작업을 방지하고 개인정보를 보호하기 위해 이 하위 에이전트가 완전히 격리된 샌드박스형 Chrome 프로필 안에서 실행된다는 점이다. 이 프로필은 활성 브라우저 로그인이나 개인 세션을 공유하거나 접근하지 않는다. 본질적으로 깨끗한 시크릿 환경처럼 작동하기 때문에, 컨텍스트 누출이나 우발적인 실제 운영을 방지하면서도 에이전트가 보안을 훼손하지 않고 UX 변경을 철저히 테스트할 수 있게 한다.
디버깅 프롬프트는 정적 코드 분석을 훨씬 넘어설 수 있다. 내장 브라우저에는 무엇이 시각적으로 정확히 잘못되었는지 지적하고 화면에서 무엇을 정확히 수정해야 하는지 정의하는 단계별 지시를 줄 수 있다.
팁
때때로 코딩 에이전트는 기존 도구, 라이브러리, 모델의 낮은 버전을 제안한다. 이는 underlying 모델이 특정 시점까지의 데이터로 학습되었기 때문에 발생한다. 예를 들어 모델의 지식 안에는 더 이후 버전이 없어서
gemini-1.5-flash를 제안할 수 있다. 이를 방지하려면 코딩 에디터의 RAG 기능을 사용해 최신 문서를 추가하거나, 문서를 Markdown 파일로 내려받아 스펙 폴더 안에 넣을 수 있다. Agent Skills나 프로필 프롬프트에도 이 정보를 추가할 수 있다. 에이전트는 쉽게 학습 데이터로 되돌아가므로, 제안된 버전 번호는 항상 이중 확인해야 한다.
4. 문서 작성: 저자
SDD에서 문서는 진실의 원천이다. 문서와 코드가 동기화되어 있지 않으면 AI는 환각을 시작한다. Agent “skills” 안에 README.md 또는 CHANGELOG.md의 지시사항을 항상 유지해야 한다고 명시하라.
Python에는 Google Style Docstrings를, TypeScript에는 JSDoc을 사용하라. 이들은 함수가 무엇을 하는지 AI와 인간이 모든 로직을 한 줄씩 읽지 않고도 정확히 이해하도록 돕는 구조화된 주석 작성 방식이다.
5. 데이터 엔지니어링: 사서
테이블을 쿼리하거나 파일을 이동할 때의 역할은 데이터 엔지니어다. Google Cloud Data Extension5 같은 IDE 확장을 사용해 에디터에서 클라우드 데이터에 직접 접근하라. 출력 생성에 사용한 구체적인 SQL 쿼리나 명령을 항상 보여 주도록 에이전트에게 프롬프트하라.
MCP: 하나의 통합, 모든 프레임워크
MCP는 Anthropic이 만들었으며 이제 공개 표준이다. 사람들은 이를 “AI 도구용 USB-C”라고 부르길 좋아한다. 다소 과장된 표현이지만, 비유 자체는 아이디어를 잘 담고 있다. 데이터베이스, API, 파일 시스템을 위한 MCP 서버를 하나 만들면, MCP와 호환되는 어떤 에이전트든 맞춤 통합을 새로 작성하지 않고 그것을 사용할 수 있다.
MCP 서버 구축하기
다음은 SQLite 데이터베이스를 노출하는 약 40줄짜리 실제 서버다.
Snippet 1:
mcp_server.py- 이 스니펫은 Python SDK를 사용해 SQLite 데이터베이스를 도구 집합으로 노출하는 MCP 서버를 구현한다.
1 | # mcp_server.py - MCP를 통해 SQLite 데이터베이스를 노출한다. |
MCP 클라이언트 연결하기
Snippet 2:
mcp_client.py- 이 예시는 MCP 클라이언트가 stdio를 통해 로컬 서버에 연결하여 도구를 발견하고 호출하는 방법을 보여 준다.
1 | from mcp import ClientSession, StdioServerParameters |
팀 문화와 프로세스의 진화
현대적인 코딩 에이전트와 함께 일하려면 사고방식과 팀 문화가 바뀌어야 한다. 현대적인 도구를 쓰면서 낡은 프로세스에 매달리는 것은 마차에 제트 엔진을 붙이려는 것과 같다. 이 기술은 20년 된 워크플로에 그냥 덧붙인다고 날아오르지 않는다.
풀 리퀘스트(PR)가 거대해지고, 그것을 더 작은 덩어리로 나눌지 고민하는 상황을 상상해 보라. 개발자들이 같은 파일에 손을 대면서 병합 충돌이 갑자기 늘어난다. 풀어내기 어려운 의존성 사슬이 생긴다. PR #1은 PR #2 없이는 병합할 수 없고, PR #2는 PR #3이 필요하지만, PR #3은 다른 시간대에 있는 리뷰어에게 막혀 있다. 어떤 변경은 승인되었지만 관련 변경은 리뷰 대기 중이어서 충돌이 더 늘어난다. 이제 갑자기 망가진 브랜치에 갇히게 된다.
이런 문제를 범주별로 나누어 보자.
- 병합 충돌: 여러 개발자가 한 시간 안에 같은 파일에 변경사항을 반영한다.
- 리뷰 교착: 거대한 PR이 하위 PR의 러시아 인형처럼 변한다.
- 컨텍스트 단편화: 개발자가 자리를 비운 사이 팀원이 공유 파일에서 변수 이름을 바꾼다. 에이전트는 오래된 스냅샷을 인용하며 더 이상 존재하지 않는 함수를 호출하는 코드를 만든다.
이제 몇 가지 교훈을 살펴보자.
코드 리뷰
AI가 생성한 커밋의 양과 규모를 번아웃 없이 견디려면 팀은 새로운 가이드라인을 탐색해야 한다. 이상적인 워크플로는 논쟁의 여지가 있지만, 코드를 작성하는 일에서 그것을 통합하는 일로 전환하는 과정을 관리하는 데 도움이 되는 몇 가지 아이디어는 다음과 같다.
고속 통합을 위한 전략
- 묶음 요약과 위험 평가: 모든 PR에 무엇이 바뀌었는지, 잠재적인 파손 지점은 어디인지, 위험 평가는 무엇인지에 대한 AI 생성 스냅샷을 포함하도록 요구하는 것을 고려하라. 이는 Markdown 파일이나 상세한 커밋 설명일 수 있으며, 인간 리뷰어가 줄 단위에 매몰되지 않고 아키텍처 영향에 집중하도록 돕는다.
- 소유권의 재구상: 인간 리뷰의 초점을 폐기 가능한 에이전트 작성 코드의 스타일 꼬투리 잡기에서 아키텍처 청사진의 무결성 보장으로 옮겨라. 스타일 문제는 공유 문법 린터나 작업공간 특화 스타일북, 예를 들어
SKILLS.md같은 자동 통합 도구로 처리할 수 있다. - 조건부 LGTM: 시간대가 다른 팀에서 12시간 지연을 없애기 위해 “조건부 LGTM(Looks Good To Me)”을 도입할 수 있다. 리뷰어는 모든 자동 테스트를 통과한다는 조건으로 PR을 승인한다. 테스트가 녹색이 되면 코드는 자동으로 병합된다.
- 비난 없는 문화 정의: 고속 환경에서는 가장 많은 코드를 생산하는 사람이 버그나 병합 충돌의 희생양이 되기 쉽다. 이런 문제를 에이전트를 사용하는 개인 개발자의 문제가 아니라 깨진 통합 프로세스의 문제로 귀속하는 방법을 논의하는 것이 도움이 된다.
- 에이전트 코드 리뷰 사용: 대신 코드 리뷰를 수행하는 Skill을 만들 수 있다. 코드 리뷰에 응답하는 Skill도 작성할 수 있다. 아래의 코드 스니펫을 보라. GitHub Actions6 또는 GitHub의 Gemini Code Assist7를 사용해 이를 자동화할 수 있다.
마지막으로 이런 질문을 던지고 논의할 수도 있다. 여러 에이전트로 구성된 스쿼드와 일할 수 있다면, 굳이 팀으로 일할 필요가 있을까? 그래도 팀으로 일하기로 결정했다면, 팀원들이 같은 파일을 거의 건드리지 않도록 작업을 나누는 방법을 탐색할 수 있다. 예를 들어 API와 UX에 대한 명확한 소유권을 지정하는 식이다. 겹침이 필요할 때는 지정된 “부분 소유자”가 최종 동기화를 처리할 수 있다.
Snippet 3:
code-check.md- 이 Skill은 보안 및 로직 기준에 따라 자동 코드 리뷰를 수행하는 구조화된 워크플로를 정의한다.
1 | Senior Software Engineer이자 Security Researcher로 행동하라. 제공된 GitHub PR 또는 Diff의 코드를 다음 엄격한 기준에 따라 검토하라. |
레포를 감시하는 에이전트 배포하기
훌륭한 리뷰 프롬프트를 작성할 수는 있다. 하지만 누가 모든 PR마다, 매일 밤 스윕마다, 인간이 버튼을 누르지 않아도 그것을 실행할 것인가?
코드 리뷰 Skill은 IDE 안에서 호출할 때 실행된다. 다음 단계는 이를 지속적 코드 분석 에이전트로 배포하는 것이다. 이 에이전트는 저장소를 감시하고, PR 열림이나 야간 크론 같은 이벤트에 반응하며, 누구도 요청하지 않아도 결과를 다시 게시한다. 금요일 오후에 지친 인간이 놓치는 것을 잡아낸다. 예를 들어 새 CVE가 생긴 의존성, 6개월 전의 TODO가 조용히 보안 구멍으로 변한 것 같은 문제다. 팀이 AI 생성 PR을 대량으로 출하하기 시작하면, 지속적 리뷰어는 그 산출량에 맞춰 확장되는 유일한 것이다. 문제는 얼마나 맞춤형으로 가야 하느냐다. 답은 세 단계의 스펙트럼이며, 각 단계는 제어권과 단순성을 서로 교환한다.
스펙트럼
세 단계의 차이는 누가 런타임을 소유하는가, 그리고 누가 리뷰 기준을 작성하는가에 있다.
Tier 1 - 관리형
예를 들어 GitHub의 Gemini Code Assist8 또는 SaaS PR 리뷰어. 기성 경로다. GitHub 또는 GitLab 조직에서 활성화하면 모든 PR에 AI 리뷰어가 붙어 스타일, 버그, 보안에 대해 기본적으로 댓글을 단다. 작성할 프롬프트도 없고, 관리할 인프라도 없다. 좌석당 비용을 지불하면 된다. 대가는 이렇다. 당신의 리뷰 의견이 아니라 벤더의 리뷰 의견을 얻게 된다. 일반 리뷰어는 엄격한 사내 스타일이나 도메인 특화 위험 프로필, 예를 들어 HIPAA, PCI, 내부 SDK 같은 것이 중요한 팀에서 중요한 부분을 놓친다.
Tier 2 - 하이브리드
예를 들어 코딩 에이전트 CLI, 즉 Antigravity CLI9를 트리거하는 GitHub Action6. 중간 경로이며 대부분의 팀에게 적절한 시작점이다. 앞서 나온 code-check.md처럼 자신만의 리뷰 Skill을 작성하고, 저장소에 커밋한 뒤, 비대화형 모드로 선택한 CLI를 실행하고 그 결과를 PR 댓글로 게시하는 CI 액션에서 트리거한다. 런타임은 CI 제공자가 소유한다. 프롬프트, 모델 선택, 샌드박싱, 리뷰 기준은 당신이 소유한다.
Tier 3 - 커스텀
예를 들어 Gemini Enterprise Agent Engine10의 ADK 에이전트. 완전히 소유하는 경로다. 예를 들어 리뷰어를 ADK 에이전트로 설정하고, 지속 가능한 세션과 Memory Bank를 갖춘 관리형 런타임을 위해 Agent Runtime에 배포하며, 소스 호스트의 웹훅 이벤트와 연결할 수 있다. 리뷰어가 여러 PR에 걸친 리팩터링의 컨텍스트를 유지해야 하거나, “이 서비스를 컴플라이언스 드리프트 관점에서 감사하라”는 작업을 플래너와 하위 에이전트 패턴으로 수백 개의 하위 작업으로 분해해야 하거나, A2A11를 통해 다른 에이전트와 조율해야 할 때 이것이 올바른 답이다. 대가는 평가, 관측 가능성, 비용, 그리고 프로덕션에서 실패했을 때의 온콜 로테이션까지 모두 소유한다는 것이다. 이런 아키텍처의 예시는 Siemens 사례 연구17에서 볼 수 있다.
어떤 단계가 필요한지는 세 가지 질문이 알려 준다.
리뷰 기준이 얼마나 구체적인가?
일반적이라면 Tier 1.
팀 또는 저장소 특화라면 Tier 2 또는 Tier 3.
에이전트가 실행 간에 무언가를 기억해야 하는가?
아니면 Tier 1 또는 Tier 2.
그렇다면, 즉 코드베이스 메모리나 PR 간 컨텍스트가 필요하다면 Tier 3.
잘못되었을 때 최악의 상황은 무엇인가?
시끄러운 댓글 하나라면 어떤 단계든 가능하다.
병합된 회귀나 유출된 비밀값이라면 모든 도구 호출 앞에 이전 섹션의 Policy Server 패턴을 둔 Tier 3가 필요하다.
대부분의 팀은 관리형 리뷰어가 특정한 것을 놓치는 순간 자신의 단계가 무엇인지 알게 된다. 예를 들어 중견 핀테크의 플랫폼팀은 Tier 1에서 시작했지만, 곧 컴플라이언스 리뷰어가 감사인이 이미 승인한 보일러플레이트를 지적하면서도 정작 중요한 패턴, 즉 로그 문에 마스킹되지 않은 PII가 들어간 경우를 놓친다는 사실을 발견했다. GitHub Action에 연결한 40줄짜리 compliance-check.md Skill, 즉 Tier 2는 일주일 안에 거짓 양성 댓글을 크게 줄였다. Tier 3는 아직 필요하지 않았다.
완전한 규모의 Tier 3: 그래프 네이티브 코드 이해
커스텀 코드 리뷰 런타임(Tier 3)은 단일 ADK 에이전트가 diff를 읽는 수준보다 훨씬 더 확장된다. 같은 아키텍처는 1억 줄짜리 레거시 코드베이스에서 진지한 리뷰어가 필요로 하는 더 무거운 구성 요소도 지원한다. 코드 구조를 담은 그래프 데이터베이스, 의미 검색을 위한 벡터 저장소, 분해를 위한 하위 에이전트 파이프라인이 그 예다. 그런 규모에서 코드를 평평한 텍스트로 컨텍스트 윈도우에 넣는 방식은 공간이 부족해지고, 표준 RAG는 코드를 읽을 수 있게 만드는 구조를 제거한다. 클래스는 파일에 속하고, 함수 호출은 10년 전에 작성된 요구사항 문서로 이어진다. 이것을 벡터 저장소로 평탄화하면 지도는 사라진다.
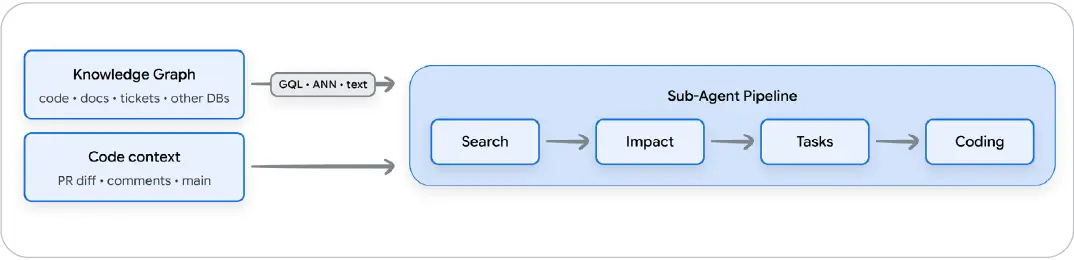
그림 1: 커스텀 코드 리뷰 런타임 아키텍처 예시
가장 큰 레거시 현대화 프로젝트에서 등장한 패턴은 에이전트를 지식 그래프 위에 구축하는 것이다. 코드, 문서, 티켓, 설계 PDF를 Spanner Graph12 같은 그래프 데이터베이스에 수집한 뒤, 에이전트가 세 가지 검색 모드를 조합하게 한다. 구조적 질의, 예를 들어 “payment.process()를 전이적으로 호출하는 모든 함수”에는 그래프 순회(GQL)를 사용한다. 의미 질의, 예를 들어 “이 문단이 설명하는 일을 하는 코드를 찾아라”에는 노드 임베딩에 대한 벡터 검색(ANN)을 사용한다. 정확한 식별자 일치에는 전체 텍스트 검색을 사용한다. 이 조합은 “이것을 바꾸면 무엇이 깨지는가?”라는 질문에 자신감 있는 추측 대신 정밀한 영향 지도를 제공한다.
두 번째 절반은 분해다. 단일 에이전트에게 “이 모듈을 리팩터링하라”고 말하면 실패한다. 같은 작업을 ADK13 하위 에이전트 파이프라인, 즉 그래프를 탐색하는 Search 에이전트, 요구사항을 포착하는 Story 에이전트, 부작용을 예측하는 Impact 에이전트, 원자적 작업 단위를 생성하는 Task-breakdown 에이전트, 그리고 마지막 Coding 에이전트로 나누면 작업은 관리 가능해진다. 백만 줄 코드베이스에서 프로덕션 파일럿은 동등한 리팩터링 작업을 2주에서 몇 시간으로 줄였다. 이것이 완전한 규모의 Tier 3다. PR을 감시하는 에이전트가 아니라, PR이 존재하는 시스템 전체를 이해하는 에이전트다.
관리형 코드 리뷰 런타임(Tier 1)은 몇 분 안에 일반 리뷰어를 제공한다. 하이브리드 코드 리뷰 런타임은 하루 안에 당신만의 리뷰어를 제공한다. 커스텀 코드 리뷰 런타임(Tier 3)은 런타임과 평가를 소유하는 비용을 치르는 대신 전체 시스템을 이해하는 리뷰어를 제공한다. 중요한 것을 잡아내는 가장 낮은 단계를 선택하라.
지속 가능성
우리는 새로운 현상을 보고 있다. 승인 피로다. CNBC가 보도한 Quantum Workplace 연구에 따르면, AI를 자주 사용하는 사람은 사용하지 않는 사람보다 높은 번아웃을 경험할 가능성이 45% 더 높다14. 단일 줄 개선, 도구 호출 조정 같은 지속적인 미세 승인 요청에 직면하면 개발자는 반사적으로 “Approve”를 클릭하기 시작한다. 이는 낮은 수준의 피로 형태다. 팀은 기계의 속도를 따라잡기 위해 기계의 작업을 확인하지 않게 되고, 개발자가 세부 사항에 대한 주의를 놓칠 위험이 생긴다.
팀을 보호하려면 지속적인 감독에서 구조화된 경계로 이동할 수 있다.
- 디지털 조용한 시간: 승인 요청이 저녁과 주말로 번지지 않도록 경계를 설정한다.
- 에이전트 인사이트 세션: 개발자가 AI 동료가 식별한 패턴을 공유하는 주간 세션을 열어, 고립된 발견을 공유 조직 지식으로 바꾼다.
제로 트러스트 개발: 안전망 구축하기
지금까지 초점은 리뷰와 팀 문화 쪽에 있었다. 그러나 에이전트가 충분한 가드레일 없이 행동할 때 무슨 일이 벌어지는지에 관한 또 다른 교훈이 있다.
일상적인 코드 업데이트 중에 Antigravity 내장 UI 브라우저의 힘과 한계가 발견되었다. 이 기능은 AI 에이전트가 로그인 자격 증명 없이 개발 중인 애플리케이션과 상호작용할 수 있게 해 주므로 UX 테스트에 매우 유용하다. 그러나 YOLO, 즉 자동 승인 모드에서는 인간이 생각하는 것보다 더 빨리 행동할 수 있다.
버튼을 만들라는 단순한 프롬프트 하나가 예상치 못한 연쇄 반응을 일으켰다. 브라우저 에이전트가 새 버튼을 자율적으로 클릭했는데, 그 버튼은 이메일 에이전트를 위한 것이었다. URL이 지정되어 있지 않자 에이전트는 환각을 일으켜 이메일 안전장치가 없는 폐기된 레거시 에이전트에 연결했다. 결과는 무엇이었을까? 동료 50명이 환각된 내용으로 가득 찬 거짓 이메일을 받았다.
이 사고는 컨텍스트 환각 위험을 보여 주었다. AI가 충분한 데이터를 갖고 있지 않을 때, 하드코딩된 이메일 주소나 URL 같은 민감한 정보를 포함해 자신의 컨텍스트 안에 존재하는 어떤 문자열이든 사용해 빈칸을 채우는 경우가 있다. 단순히 이메일이라면 사소해 보일 수도 있다. 그러나 에이전트가 무엇을 하고 있었는지 생각해 보라. 에이전트는 자신이 사용 가능한 데이터로 지시를 이행하고 있었고, 그렇게 해야 하는지에 대한 점검은 전혀 없었다. 이것이 자율 시스템의 핵심 위험이다. Human-in-the-Loop나 정책 엔진이 없으면 에이전트는 찾을 수 있는 모든 것을 사용해 목표를 최적화한다. 가드레일은 선택 사항이 아니다. 유용한 도구가 예측 불가능한 도구로 변하지 않게 하는 것이 바로 가드레일이다.
가드레일 구현하기
에이전트형 AI의 경계를 밀어붙일수록 역설을 마주하게 된다. 에이전트는 복잡한 문제를 해결할 만큼 자율적이어야 하지만, 엔터프라이즈 환경에서 통제에서 벗어나는 위험은 감당할 수 없다.
고객 분쟁을 “해결”하라는 임무를 받은 에이전트를 상상해 보자. 효과적으로 일하려면 고객 데이터, 이메일 도구, 내부 시스템에 접근해야 한다. 하지만 과제는 그것이 실수로 전체 데이터베이스에 이메일을 보내거나 독점 코드를 공유하지 않도록 보장하는 것이다.
자율 에이전트는 결정론적이 아니라 확률적인 LLM에 의해 구동된다. 시스템 프롬프트에 제약을 하드코딩하는 방식은 취약하다. 컨텍스트는 넘치고, 에이전트는 프롬프트 인젝션을 통해 규칙을 우회하도록 “설득”될 수 있다. 프로덕션급 플랫폼을 구축하려면 외부에 있고 변조 불가능한 거버넌스가 필요하다. 악성 코드에 맞서 에이전트를 보호하고 평가하는 방법은 Day 4 백서인 Vibe Coding Agent Security and Evaluation에서 더 자세히 읽을 수 있다.
샌드박싱
문자열을 정화하는 것을 넘어, 진정한 보안에는 에이전트의 행동을 가두는 제한된 실행 환경, 즉 샌드박스가 필요하다. 엄격한 출력 필터링이 있더라도 LLM은 문법적으로는 유효하지만 논리적으로는 악의적인 코드를 생성할 수 있고, 이는 호스트 시스템을 손상시킬 수 있다. 에이전트가 주도하는 작업을 기본 네트워크와 민감한 파일 시스템에서 격리된 일시적이고 낮은 권한의 컨테이너 안에서 실행하면, 핵심 인프라를 보호하는 폭발 반경이 만들어진다. 이 모델에서 에이전트가 파괴적인 명령을 실행하도록 속더라도 피해는 결과 없이 지우고 초기화할 수 있는 폐기 가능한 인스턴스 안에 갇힌다.
Antigravity 안에서는 단일 토글로 이 안전망을 강제할 수 있다. User Settings로 이동해 “Terminal Sandboxing”15을 활성화하라. 또는 팀을 위한 휴대 가능하고 클라우드 기반인 샌드박스가 필요하다면 에이전트의 작업공간을 컨테이너화할 수 있다. 공식 Gemini CLI 샌드박스16 이미지를 기반으로 하는 커스텀 Dockerfile, 예를 들어 .gemini/sandbox.Dockerfile을 작성하면 제한된 클라우드 자격 증명을 주입할 수 있고, 터미널에서 export GEMINI_SANDBOX=docker를 설정해 CLI 도구가 Docker 안에서만 실행되도록 강제할 수 있다. 두 모델 모두에서 에이전트가 악의적인 실행에 속더라도 커널 수준에서 강한 권한 오류를 만나며, 호스트 시스템은 완전히 손대지 않은 상태로 남는다.
Human-in-the-Loop
자동화가 목표이긴 하지만, 고위험 작업에는 궁극적인 안전장치 역할을 하는 Human-in-the-Loop(HITL) 프로토콜이 필요하다. 이는 프로덕션에 코드 배포, 데이터베이스 스키마 수정, 금융 거래 시작처럼 특정 위험 프로필을 만족하는 작업에 대해 “체크포인트” 게이트를 구현하는 것을 뜻한다. 에이전트의 정화된 의도를 인간 감독자에게 제시해 수동 승인을 받게 하면, AI의 속도와 개발자의 섬세한 판단을 균형 있게 결합할 수 있다. 이는 에이전트가 무거운 작업을 수행하더라도, 아키텍처 무결성에 대한 최종 책임은 확고히 인간의 손에 남도록 보장한다.
AI가 생성한 테스트 커버리지
AI 생성 코드의 급증은 안정적인 안전망을 유지하기 위해 수동 테스트에서 AI 생성 테스트 커버리지로의 전환을 만든다. 고속 환경에서는 기계에게 자신의 출력을 검증하는 테스트 자체를 작성하게 함으로써 “테스트 주도 개발”이 현실이 된다.
이 과정은 에이전트가 수정을 시도하기 전에 먼저 실패 단위 테스트 또는 curl 요청 같은 재현 명령을 만들도록 강제하는 것을 포함한다. 이러한 자동 테스트를 코드베이스에 포함하면 빠른 반복마다 검증 가능한 검사 스위트가 뒷받침된다. 이는 버그가 돌아오는 것을 막고, 인간 리뷰어가 통합을 위한 자동 녹색 신호를 신뢰할 수 있게 한다.
평가
ML 모델을 사용하는 코드에 왜 특별한 품질 검사가 필요할까? 전통적인 소프트웨어 테스트는 출력이 계산되는 것이 아니라 생성되는 시스템에는 충분하지 않다. 에이전트, 또는 분류기, 요약기, 검색기처럼 ML로 구동되는 구성요소는 자신의 도구에 대한 단위 테스트 100개를 통과하고도 잘못된 도구를 선택하거나, 중요한 답을 다른 말로 바꾸거나, 사실을 환각함으로써 극적으로 실패할 수 있다. 오류 여지는 제거해야 할 결함이 아니라 모델의 고유 속성이다. 따라서 테스트 전략은 그것을 수용해야 한다.
평가는 이 간극을 이진 단언 대신 점수화된 판단과 허용 범위로 대체함으로써 메운다. 단위 테스트는 “함수가 올바른 값을 반환했는가?”를 묻는다. 답은 이진적이다. 평가는 “에이전트의 행동이 최소한 기준선만큼 좋은가?”를 묻는다. 여기에는 LLM-as-Judge가 주는 0-5 점수, 도구 호출의 순서 변동을 허용하는 궤적 검사, 단언이 뒤집혔을 때가 아니라 품질이 설정 가능한 여유폭 아래로 떨어졌을 때 작동하는 게이트가 포함된다. 테스트는 결정론적 회귀를 잡고, 평가는 행동 드리프트를 잡는다.
정책 서버
다음은 외부 시스템에 도달하기 전에 행동을 가로채는 하이브리드 정책 서버 예시다. 이 서버는 두 계층으로 작동한다.
- 구조적 게이팅, 즉 신호등: 역할과 환경에 기반한 결정론적 규칙이다. 빠른 이진 검사이며, 예를 들어 viewer 역할은
send_email도구를 사용할 수 없다는 식이다. 이 계층은 LLM에게 묻지 않고 아키텍처 위반을 막는다. - 의미적 게이팅, 즉 지능형 심판: Gemini 같은 보조 특화 LLM을 사용해 제안된 행동의 의도와 내용을 자연어 개인정보보호 지침에 비추어 검사한다. 이는 도구 자체는 허용되지만, 사용 방식이 정책을 위반하는 경우에 필요하다. 예를 들어 admin은
send_email을 사용할 수 있지만, 평문 이메일 주소나 API 키처럼 마스킹되지 않은 PII를 보내서는 안 된다. 이 지점에서 구조적 규칙은 실패한다. 가능한 모든 PII 유출을 정규식으로 잡을 수는 없다.
이 규칙들은 표준 policies.yaml에 정의된다.
Snippet 4:
policies.yaml- 이 설정은 역할과 환경에 기반한 도구 수준 권한에 대해 결정론적 게이팅 규칙을 수립한다.
1 | environments: |
아래는 런타임에 도구 호출을 가로채고 권한을 검증하도록 설계된 Policy Server의 가벼운 구현이다.
Snippet 5:
policy_server.py- 이 서비스는 행동을 가로채고 구조적·의미적 평가를 수행하는 하이브리드 정책 엔진을 구현한다.
1 | import os, yaml |
코드 목록은 다음처럼 작동한다. 에이전트가 도구를 사용하기로 결정하면 실행 흐름이 가로채진다.
- 구조적 검사: 이 역할/환경에서 도구가 허용되는가? YAML을 확인한다.
- 의미적 검사: 인수가 안전한가? Gemini에게 묻는다. 코드 스니펫의 프롬프트를 보라. 마스킹되지 않은 이메일 주소는 위반으로 간주된다.
- 실행: 둘 다 통과하면 도구가 실행된다. 그렇지 않으면 “Policy Violation” 메시지가 에이전트에게 반환되어, 에이전트가 스스로 수정하거나 우아하게 실패할 수 있다.
이 구조는 실행 로직과 거버넌스 로직을 분리하는 안전망을 만든다. 이는 엔터프라이즈 소프트웨어에서 중요한 관심사의 분리다.
컨텍스트 위생과 프롬프트 정화
자율 개발에서 중요한 위험은 컨텍스트 환각이다. 에이전트에게 특정 데이터가 없을 때, 현재 컨텍스트 안의 어떤 문자열이든 사용해 빈칸을 채울 수 있고, 그 과정에서 하드코딩된 이메일 주소나 비공개 URL 같은 민감한 정보가 누출될 수 있다.
이를 완화하려면 PII 마스킹과 자리표시자 주입을 수행하는 미들웨어를 통해 엄격한 컨텍스트 위생을 구현해야 한다. 개인 식별 정보를 템플릿 안의 일반 자리표시자로 대체함으로써, 에이전트가 정화된 데이터 위에서 작동하도록 보장한다.
더 나아가 모든 에이전트 출력은 프롬프트 인젝션과 통제되지 않는 UI 상호작용을 방지하기 위해 정화되어야 한다. 이렇게 해야 기계의 “바이브”가 결코 아키텍처 취약점으로 번역되지 않는다.
동적 ContextResolver 구현하기
이 보안 패턴은 애플리케이션 핵심 코드베이스 안에 가벼운 정규식 기반 변환 유틸리티를 구현함으로써 달성된다. 아래는 이 설계의 실용적 구현이다.
이 스크립트는 핵심 변환 엔진으로 작동하며, 이중 대괄호 문법 [[VARIABLE_NAME]]으로 구조화된 자리표시자 문자열을 런타임 오버라이드 또는 환경 설정으로 대체한다.
Snippet 6:
context_resolver.py- 이 유틸리티는 컨텍스트 위생을 유지하기 위해 대괄호 자리표시자를 환경 변수로 해석한다.
1 | import os |
컨텍스트 위생을 전역적으로 강제하려면, 정화 유틸리티를 에이전트 실행 파이프라인에 검증 단계로 직접 연결해야 한다. 들어오는 도구 호출이 실행되기 전에 가로채면, 프롬프트가 주입된 모든 문자열을 동적으로 정화할 수 있다.
Snippet 7:
tool_policy_engine.py- 이 미들웨어는 도구 인수가 실행되기 전에 정화되도록 컨텍스트 리졸버를 에이전트 파이프라인에 통합한다.
1 | # ... validate_tool_call 프레임워크 실행 내부 ... |
이 경계를 강제하면, 에이전트가 이메일 전송이나 클라우드 프레젠테이션 조회 같은 행동을 실행하려는 모든 시도가 가로채진다. 엔진은 [[COMMENTER_EMAIL]] 또는 [[DEFAULT_PRESENTATION_ID]] 같은 일반 자리표시자를 승인된 테스트 자산으로 안전하고 조용히 변환한다. 그 결과 테스트 스위트나 시스템 프롬프트에 민감한 PII를 하드코딩할 필요 자체가 사라진다.
요약
1년도 채 되지 않아 소프트웨어 개발 주기는 극적으로 빨라졌다. 에이전트가 점심시간까지 문서화가 잘 된 코드 수천 줄을 만들어 내는 모습을 보는 것은 중대한 진전이다.
하지만 그 속도는 중요한 변화를 드러냈다. AI는 코드 생산 병목을 제거했고, 제약은 그 출력을 검토하고 테스트하고 통합해야 하는 인간 쪽으로 이동했다. 이는 공유된 인지 부하다. 인간은 테스트 스펙, 통합 스펙, MLOps/DevOps 청사진을 작성하는 아키텍트로 행동하고, AI는 실제 테스트 코드 작성, 통합 수행, 세밀한 운영 세부 사항 관리라는 무거운 작업을 맡는다.
더 나은 프롬프트와 더 빠른 모델만으로는 통합 병목을 해결할 수 없다. 성공은 팀 역학을 진화시키고, 에이전트와의 협업을 다듬으며, 잠들지 않는 도구에 엄격한 경계를 설정하는 데 달려 있다. 과제는 단순한 코드 생산에서, 작업을 검증하고 통합하고 배포하는 시스템의 오케스트레이션으로 이동했다.
어디서 시작할 것인가
에이전트 코드베이스에서 이러한 패턴을 운영하려는 팀의 경우, uv google-agents-cli setup은 코딩 에이전트 안에 일곱 개의 Skill을 설치한다. 이 Skill들은 스캐폴딩, ADK 코드, 평가, 배포, 게시, 관측 가능성을 포괄한다. 이 백서에서 설명한 패턴은 오늘 실행할 수 있는 명령이 된다. agents-cli scaffold는 스펙 주도 프로젝트 생성을, agents-cli eval run은 AI 생성 테스트 커버리지 게이트를, agents-cli deploy는 Cloud Run 또는 Vertex AI Agent Engine으로의 샌드박스형 배포를 수행한다.
Endnotes
-
1Google, 2026, Antigravity, agentic development platform. Available at: https://antigravity.google ↩
-
2Google for Developers, 2025, Gemini CLI, Query and edit large codebases, generate apps from images or PDFs, and automate complex workflows - all from your terminal with Gemini 3. Available at: https://geminicli.com ↩
-
3Ouyang Y., et al., 2026, SkCC: Portable and Secure Skill Compilation for Cross-Framework LLM Agents. Available at: https://arxiv.org/abs/2605.03353 ↩
-
4Cucumber Open Source Project, 2026, Gherkin Syntax Reference. Available at: https://cucumber.io/docs/gherkin/reference ↩
-
5Google Cloud, 2026, Data Agent Kit extension for VS Code overview. Available at: https://docs.cloud.google.com/data-cloud-extension/vs-code/overview ↩
-
6GitHub, 2026, Quickstart for GitHub Actions. Available at: https://docs.github.com/en/actions/get-started/quickstart ↩
-
7Google, 2026, Set up Gemini Code Assist on GitHub. Available at: https://developers.google.com/gemini-code-assist/docs/set-up-code-assist-github#consumer ↩
-
8GitHub, 2026, Gemini Code Assist on GitHub Marketplace. Available at: https://github.com/marketplace/gemini-code-assist ↩
-
9Google, 2026, Antigravity CLI Overview. Available at: https://antigravity.google/docs/cli-overview ↩
-
10Google Cloud, 2025, Agent Engine Overview. Available at: https://cloud.google.com/vertex-ai/generative-ai/docs/agent-engine/overview ↩
-
11The Linux Foundation, 2025, Agent 2 Agent (A2A) Protocol. Available at: https://a2a-protocol.org/latest/ ↩
-
12Google Cloud, 2025, Spanner Graph Documentation. Available at: https://cloud.google.com/spanner/docs/graph ↩
-
13Google ADK, Build powerful multi-agent systems with the Agent Development Kit Documentation. Available at: https://google.github.io/adk-docs/ ↩
-
14CNBC, 2025, Working smarter, not harder: AI could help fight burnout - but is it? Available at: https://www.cnbc.com/2025/09/20/working-smarter-not-harder-how-ai-could-help-fight-burnout-.html ↩
-
15Google, 2026, Sandboxing Terminal Commands. Available at: https://antigravity.google/docs/sandbox-mode ↩
-
16Google, 2026, Sandboxing in Gemini CLI. Available at: https://geminicli.com/docs/cli/sandbox ↩
-
17Google Cloud, 2026, How Siemens “slices the elephant,” advancing agentic workflows for industrial software development. Available at: https://cloud.google.com/blog/products/ai-machine-learning/how-siemens-sliced-the-elephant-modernizing-legacy-code-with-agentic-workflows/?e=48754805 ↩
댓글
GitHub 계정으로 의견을 남길 수 있습니다. 댓글은 GitHub Discussions에 저장됩니다.